
If you like this piece and want to support my independent reporting and analysis, why not subscribe to my premium newsletter?
It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5,000 to 18,000 words, including vast, detailed analyses of NVIDIA, Anthropic and OpenAI’s finances, and the AI bubble writ large. I just put out a massive Hater’s Guide To The SaaSpocalypse, as well as last week’s deep dive into How AI Isn't Too Big To Fail.
Subscribing helps directly support my free work, and premium subscribers don’t see this ad in their inbox.
I can’t get over how weird the AI bubble has become.
Hyperscalers are planning to spend over $600 billion on data center construction and GPUs predominantly bought from NVIDIA, the largest company on the stock market, all to power generative AI, a technology that’s so powerful that none of them will discuss how much it’s making them, or what it is we’re all meant to be so excited.
To make matters weirder, Microsoft, a company that spent $37.5 billion in capital expenditures in its last quarter on AI, recently updated the terms and conditions of its LLM-powered “Copilot” service to say that it was “for entertainment purposes only,” discussing a product that apparently has 15 million users as part of enterprise Microsoft 365 subscriptions, and is sold to both local and national governments overseas, including the US federal government.
That’s so weird! What’re you doing Microsoft? What do you mean it’s for entertainment purposes? You’re building massive data centers to drive this!
Well, okay, you’re building them at some point. As I discussed a few weeks ago, despite everybody talking about the hundreds of gigawatts of data centers being built “to power AI,” only 5GW are actually “under construction,” with “under construction” meaning anything from “we’ve got some scaffolding up” to “we’re about to hand over the keys to the customer.”
But isn’t it weird we’re even building those data centers to begin with? Why? What is it that AI does that makes it so essential — or, rather, entertaining — that we keep funding and building these things? Every day we hear about “the power of AI,” we’re beaten over the head with scary propaganda saying “AI will take our jobs,” but nobody can really explain — outside of outright falsehoods about “AI replacing all software engineers” — what it is that makes any of this worthy of taking up any oxygen let alone essential or a justification for so many billions of dollars of investment.
We Are Not In The Early Days of AI, And It’s Weird To Say That We Are
Instead of providing an actual answer of some sort, AI boosters respond by saying it’s “just like the dot com bubble” — another weird thing to do considering 168,000 people lost their jobs as the NASDAQ dropped by 80% in two years, and only 16% of the world even used the internet, and those that did in America had an average internet speed of 50 kilobits per second (and only 52% of them had access in 2000 anyway). Conversely, to quote myself:
Global internet access has never been higher or cheaper, and for the most part, billions of people can access a connection fast enough to use generative AI. There is very little stopping anyone from using an LLM — ChatGPT is free, ChatGPT’s cheaper “Go” subscription has now spread to the global south, Gemini is free, Perplexity is free, and Meta’s LLM is free — where the dot com bubble was made up of stupid businesses and a lack of fundamental infrastructure to give most people the opportunity to access a reliable internet experience, basically anybody can get reliable access to generative AI.
And with that incredibly easy access, only 3% of households pay for AI. Boosters will again use this talking point to say that “we’re in the early days,” but that’s only true if you think that “early days” means “people aren’t really using it yet.”
Yet the “early days” argument is inherently deceptive.
While the Large Language Model hype cycle might have only begun in 2022, the entirety of the media and markets have focused their attention on AI, along with hundreds of billions of dollars of venture capital and nearly a trillion dollars of hyperscale capex investment. AI progress isn’t hampered by a lack of access, talent, resources, novel approaches, or industry buy-in, but by a single-minded focus on Large Language Models, a technology that has been so obviously-limited from the very beginning that Gary Marcus was able to call it in 2022.
Saying it’s “the early days” also doesn’t really make sense when faced with the rotten and incredibly unprofitable economics of AI. The early days of the internet were not unprofitable due to the underlying technology of serving websites, but the incredibly shitty businesses that people were building. Pets.com spent $400 per customer in customer acquisition costs, millions of dollars on advertising, and had hundreds of employees for a business with a little over $600,000 in quarterly revenue — and as a result, nothing about its failure was about “the early days of the internet” at all, as was the case with Kozmo, or any number of other dot com flameouts.
Similarly, internet infrastructure companies like Winstar collapsed because they tried to grow too fast and signed stupid deals rather than anything about the underlying technology’s flaws.
For example, in 1998, Lucent Technologies signed its largest deal — a $2 billion “equipment and finance agreement” — with telecommunications company Winstar, which promised to bring in “$100 million in new business over the next five years” and build a giant wireless broadband network, along with expanding Winstar’s optical networking.
Eager math-heads in the audience will be able to see the issue of borrowing $2 billion to make $100 million over five years, as will eager news-heads laugh at WIRED magazine in 1999 saying that Winstar’s “small white dish antennas…[heralded] a new era and new mind-set in telecommunications.” Winstar died two years later because its business was built to grow at a rate that its underlying product couldn’t support.
In the end, microwave internet (high-speed internet delivered via radio waves) has become an $8 billion-a-year industry, despite everybody’s excitement.
In any case, anytime that somebody tells you that we’re in “the early days of AI” has either been conned or is in the process of conning you, as they’re using it to deflect from issues of efficacy or underlying economic weakness.
In fact, that’s a great place to go next.
Why Is Everybody Lying About What AI and “Agents” Can Actually Do?
Probably the weirdest thing about this entire era is how nobody wants to talk about the fact that AI isn’t actually doing very much, and that AI agents are just chatbots plugged into an API.
Per Redpoint Ventures’ Reflections on the State of the Software and AI Market, “the agent maturity curve is still early, but the TAM implications are enormous,” with agents able to “...run discretely for minutes, [and] execute end-to-end tasks with some oversight.”
What tasks, exactly? Who knows! Truly, nobody seems able to say. To paraphrase Steven Levy at WIRED, 2025 was meant to be the year of AI agents, but turned out to be the year of talking about AI agents. Agents were/are meant to be autonomous pieces of software that go off and do distinct tasks.
In reality, it’s kind of hard to say what those tasks are. “AI agent” now refers to literally anything anybody wants it to, but ultimately means “chatbot that has access to some systems.”
The New York Times’ Ezra Klein recently talked to the entity currently inhabiting former journalist and Anthropic co-founder Jack Clark recently about “how fast AI agents would rip through the economy,” but despite speaking for over an hour, the closest we got was “it wrote up a predator-prey simulation (a complex-sounding but extremely-common kind of webgame that Anthropic likely ingested through its training material)” and “chatbots that talk to each other about tasks,” and if you think I’m kidding, this is how he described it:
But I’ve seen colleagues who write what you might think of as a version of Claude that runs other Claudes. So they’re like: I’ve got my five agents, and they’re being minded over by this other agent, which is monitoring what they do.
Anyway, this is all bad, because multiple papers have now shown that, and I quote, agents are “...incapable of carrying out computational and agentic tasks beyond a certain complexity,” with Futurism adding that said complexity was pretty low.
The word “agent” is meant to make you think of powerful autonomous systems that carry out complex and minute tasks, when in reality it’s…a chatbot. It’s always a fucking chatbot. It might be a chatbot with API access or a chatbot that generates a plan that another chatbot looks at and says something about, but it’s still chatbots talking to chatbots.
When you strip away the puffery, nobody seems to actually talk about what AI does.
Let’s take a look at CNBC’s piece on Goldman Sachs’ supposed contract with Anthropic to build “autonomous systems for time-intensive, high-volume back-office work”:
The bank has, for the past six months, been working with embedded Anthropic engineers to co-develop autonomous agents in at least two specific areas: accounting for trades and transactions, and client vetting and onboarding, according to Marco Argenti, Goldman’s chief information officer.
The firm is “in the early stages” of developing agents based on Anthropic’s Claude model that will collapse the amount of time these essential functions take, Argenti said. He expects to launch the agents “soon,” though he declined to provide a specific date.
…okay, but like, what does it do?
Argenti said the firm was “surprised” at how capable Claude was at tasks besides coding, especially in areas like accounting and compliance that combine the need to parse large amounts of data and documents while applying rules and judgment, he said.
Right, brilliant. Great. Love it. What tasks? What is the thing you’re paying for?
Now, the view within Goldman is that “there are these other areas of the firm where we could expect the same level of automation and the same level of results that we’re seeing on the coding side,” he said.
Goldman could next develop agents for tasks like employee surveillance or making investment banking pitchbooks, he said.
While the bank employs thousands of people in the compliance and accounting functions where AI agents will soon operate, Argenti said that it was “premature” to expect that the technology will lead to job losses for those workers.
Okay, great, we have two things it might do in the future, and that’s “employee surveillance” (?) and making pitchbooks.
The upshot is that, with the help of the agents in development, clients will be onboarded faster and issues with trade reconciliation or other accounting matters will be solved faster, Argenti said.
Onboarding? Chatbot. “Issues with trade reconciliation”? Chatbot connected to a knowledge base, like we’ve had for years but worse and more expensive. Oh, and “other accounting matters” will be solved faster, always with the future tense with these guys.
How about Anthropic and outsourcing body shop giant InfoSys’ “AI agents for telecommunications and other regulated industries”? Let’s go through the list of tasks and say what they mean, my comments in bold:
- Telecommunications: AI agents will help carriers modernize network operations, simplify customer lifecycle management, and improve service delivery—bringing intelligent automation to one of the most operationally complex and regulated industries in the world. Meaningless. Automation of what?
- Financial services: AI agents will help firms detect and assess risk faster, automate compliance reporting, and deliver more personalized customer interactions, such as tailoring financial advice based on a client's full account history and market conditions. Chatbot! “More-personalized interactions” are a chatbot with a connection to a knowledge system, as is any kind of “tailored financial advice.” Compliance reporting? Summarizing or pulling documents from places, much like any LLM can do, other than the fact that it’ll likely get shit wrong, which is bad for compliance.
- Manufacturing and engineering: Claude will help accelerate product design and simulation, reducing R&D timelines and enabling engineers to test more iterations before production. I assume this refers to people using Claude Code to do coding, which is what it does.
- Software development: Teams will use Claude Code to write, test, and debug code, helping developers move faster from design to production. Claude Code.
- Enterprise operations: Claude Cowork will help teams automate routine work like document summarization, status reporting, and review cycles. Literally a chatbot that deleted every single one of a guy’s photos when he asked it to organize his wife’s desktop.
How about OpenAI’s “Frontier” platform for businesses to “build, deploy and manage AI agents that do real work”?
Frontier gives agents the same skills people need to succeed at work: shared context, onboarding, hands-on learning with feedback, and clear permissions and boundaries. That’s how teams move beyond isolated use cases to AI coworkers that work across the business.
Shared context? Chatbot. Onboarding? Chatbot. Hands-on learning with feedback? Chatbot. Clear permissions and boundaries? Chatbot setting. Let’s check out the diagram!
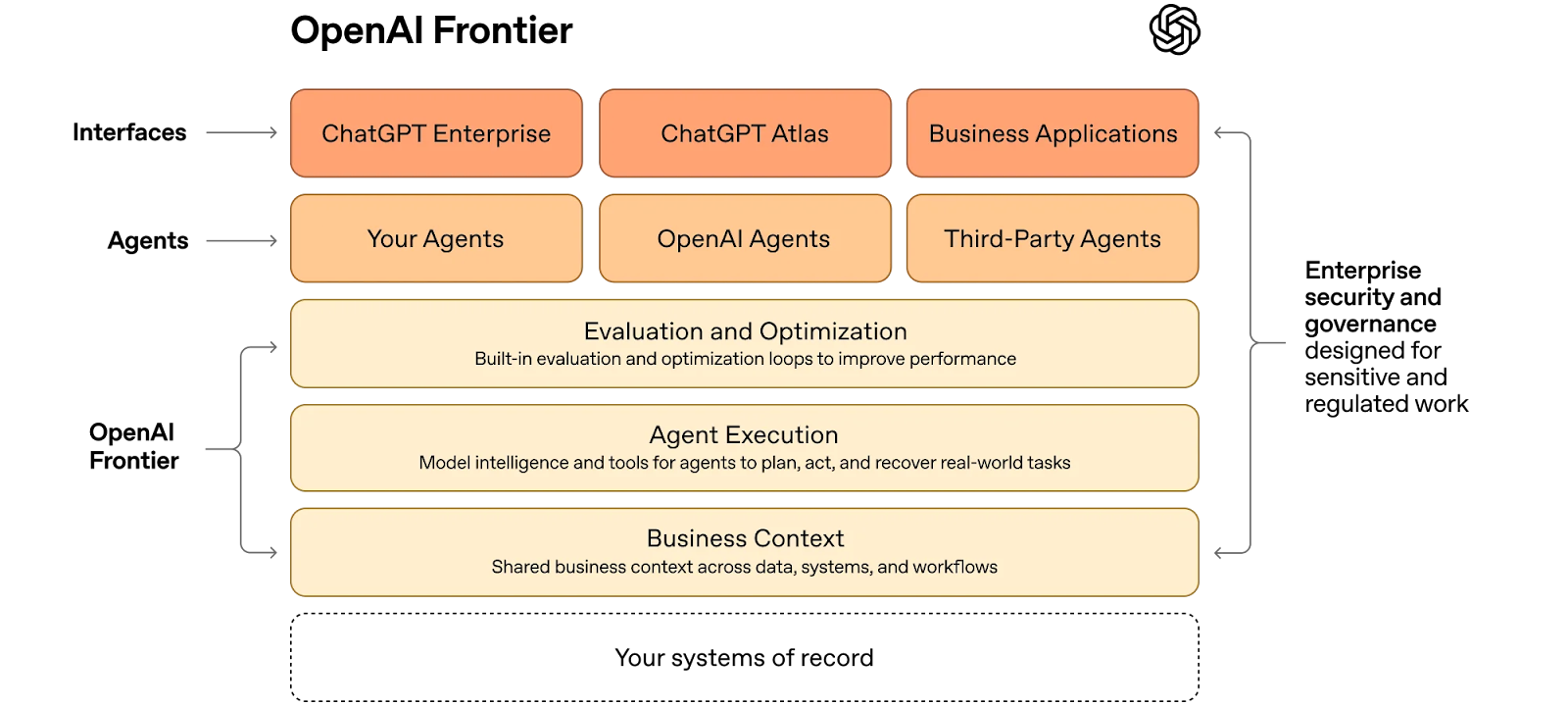
Uhuh. Great. What real-world tasks? Uhhh.
Teams across the organization, technical and non-technical, can use Frontier to hire AI coworkers who take on many of the tasks people already do on a computer. Frontier gives AI coworkers the ability to reason over data and complete complex tasks, like working with files, running code, and using tools, all in a dependable, open agent execution environment. As AI coworkers operate, they build memories, turning past interactions into useful context that improves performance over time.
Reason over data? Chatbot. “Complex tasks”? No idea, it doesn’t say. “Working with files”? Doesn’t say how it works with files, but I’d bet it can analyze, summarize and create charts based on them that may or may not have errors in them, and based on my experience of trying to get these things to make charts (as a test, I’d never use them in my actual work), it doesn’t seem to be able to do that. “Evaluation and optimization loops”? Unclear, because we have no idea what the tasks are. What are the agents planning, acting, or executing on? Again, no idea.
Yet the media continues to perpetuate the myth of some sort of present or future “agentic AI” that will destroy all employment. A few weeks ago, CNBC mindlessly repeated that ServiceNow CEO Bill McDermott believed that agents would send college grad unemployment over 30%. NowAssist, ServiceNow’s AI platform, is capable of — you guessed it! — summarization, conversational exchanges, content creation, code generation and search, a fucking chatbot just like the other chatbots.
A few weeks ago, The New York Times wrote about how “AI agents are fun, useful, but [not to] give them your credit card,” saying that they can “do more than just chat…they can edit files, send emails, book trips and cause trouble”:
Mr. Heyneman, the founder of a tiny tech start-up in San Francisco, hoped to give a speech at the World Economic Forum, the annual gathering of business leaders and policymakers in Davos, Switzerland. So he asked the bot to arrange it.
While he slept, the bot searched the internet for people connected with the event, sent them text messages and worked to negotiate a speaking spot — or at least arrange coffee with people he would like to meet. After one lengthy conversation with a businessman in Switzerland, it succeeded.
But when Mr. Heyneman woke up, he was in a pickle. Going against his original instructions, the bot had agreed to pay 24,000 Swiss francs — or about $31,000 — for a corporate sponsorship. He could not pay the bill.
Sure sounds like you connected a chatbot to your email there Mr. Heyneman.
The bots can gather information from across the internet, write reports, edit files or even send and receive messages through email and text — driving online conversations largely on their own. For people like Mr. Heyneman, these bots are almost like an employee that people can delegate work to at any time of day. In some cases, the employee is reliable. Other times, not so much.
Let’s go through these:
- “Gather information” — search tool, part of chatbots for years.
- “Write reports” — generative AI’s most basic feature, with no details on quality.
- “Edit files” — to do what exactly? Chatbot feature.
- “Send and receive messages through email and text” — generating and reading text, connected to an email account.
- “Delegate work” — what work? No need to get specific!
Yes, you can string together chatbots with various APIs and have the chatbot be able to activate certain systems. You could also do the same with a button you bought on Etsy connected to your computer via USB if you really wanted to. The ability to connect something to something else does not mean that anything useful happens at the end, and LLMs are extremely bad at the kind of deterministic actions that define the modern knowledge economy, especially when choosing to do them based on their interpretation of human language.
AI agents do not, as sold, actually exist. Every “AI agent” you read about is a chatbot talking to another chatbot connected to an API and a system of record, and the reason that you haven’t heard about their incredible achievements is because AI agents are, for the most part, fundamentally broken.
Even OpenClaw, which CNBC confusingly called a “ChatGPT moment,” is just a series of chatbots with the added functionality of requiring root access to your computer and access to your files and emails. Let’s see how CNBC described it back in February:
Marketed as “the AI that actually does things,” OpenClaw runs directly on users’ operating systems and applications. It can automate tasks such as managing emails and calendars, browsing the web and interacting with online services.
Hmmm interesting. I wonder if they say what that means:
Users have documented OpenClaw performing real-world tasks, including automatically browsing the web, summarizing PDFs, scheduling calendar entries, conducting agentic shopping, and sending and deleting emails on a user’s behalf.
Reading this, you might be fooled into believing that OpenClaw can actually do any of this stuff correctly, and you’d be wrong! OpenClaw is doing the same chatbot bullshit, just in a much-more-expensive and much-more convoluted way, requiring either a well-secured private space or an expensive Mac Mini to run multiple AI services and do, well, a bunch of shit very poorly.
The same goes for things like Perplexity’s “Computer,” which it describes as “an independent digital worker that completes and workflows for you,” which means, I shit you not, that it can search, generate stuff (words, code, images), and integrate with Gmail, Outlook, Github, Slack, and Notion, places where it can also drop stuff it’s generated.
Yes, all of this is dressed up with fancy terms like “persistent memory across sessions” (a document the chatbot reads and information it can access) with “authenticated integrations” (connections via API that basically any software can have). But in reality, it’s just further compute-intensive ways of trying to fit a square peg in a round hole, by which I mean having a hallucination-prone chatbot do actual work.
The only reason Jensen Huang is talking about OpenClaw is that there’s nothing else for Jensen Huang to talk about:
“OpenClaw opened the next frontier of AI to everyone and became the fastest-growing open source project in history,” said Jensen Huang, founder and CEO of NVIDIA. “Mac and Windows are the operating systems for the personal computer. OpenClaw is the operating system for personal AI. This is the moment the industry has been waiting for — the beginning of a new renaissance in software.”
That’s wild, man. That’s completely wild. What’re you talking about? What can NemoClaw or OpenClaw or whatever-the-fuck actually do? What is the actual output? That’s so fucking weird!
Let’s Talk About The Actual Consequences of Coding LLMs
I can already hear the haters in my head screaming “but Ed, coding models!” and I’m kind of sick of talking about them, because nobody can actually tell me what I’m meant to be amazed or surprised by.
To be clear, LLMs can absolutely write code, and can absolutely create software, but neither of those mean that the code is good, stable or secure, or that the same can be said of the software they create. They do not have ideas, nor do they create unique concepts — everything they create is based on training data fed to it that was first scraped from Stack Overflow, Github and whatever code repositories Anthropic, OpenAI, and Google have been able to get their hands on.
It’s unclear what the actual economic or productivity effects are, other than an abundance of new code that’s making running companies harder.
When a financial services company recently began using Cursor, an artificial intelligence technology that writes computer code, the difference that it made was immediate.
The company went from producing 25,000 lines of code a month to 250,000 lines. That created a backlog of one million lines of code that needed to be reviewed, said Joni Klippert, a co-founder and the chief executive of StackHawk, a security start-up that was working with the financial services firm.
“The sheer amount of code being delivered, and the increase in vulnerabilities, is something they can’t keep up with,” she said. And as software development moved faster, that forced sales, marketing, customer support and other departments to pick up the pace, Ms. Klippert added, creating “a lot of stress.”
As I wrote a few weeks ago, LLMs are good at writing a lot of code, not good code, and the more people you allow to use them, the more code you’re going to generate, which means the more time you’re either going to need to review that code, or the more vulnerabilities you’re going to create as a result. Worse still, hyperscalers like Meta and Amazon are allowing non-technical people to ship code themselves, which is creating a crisis throughout the tech industry.
Worse still, LLMs allow shitty software engineers that would otherwise be isolated by their incompetence to feign enough intelligence to get by, leading to them actively lowering the quality of code being shipped.
Per the Times:
At the same time, there are not enough engineers to review the explosion of code for mistakes. Recruiters are increasingly looking to hire senior engineers who have experience spotting errors in code and can monitor the software for risks. Open source software projects, which anyone can contribute to, have been inundated with A.I.-enabled additions. And sometimes flaws in the code can lead to security vulnerabilities or software that crashes.
The Times also notes that because LLM coding works better on a device rather than a web interface, “...engineers are downloading their entire company’s code to their laptops, creating a security risk if the laptop goes missing.”
Speaking frankly, it appears that LLMs can write code, and create some software, but without any guarantee that said code will compile, run, be secure, performant, or easy to read and maintain. For an experienced and ethical software engineer, LLMs can likely speed them up somewhat, though not in a way that appears to be documented in any academic sense, other than it makes them slower.
And I think it’s fair to ask what any of this actually means. What’s the advantage of having an LLM write all of your code? Are you shipping faster? Is the code better? Are there many more features being shipped? What is the actual thing you can point at that has materially changed for the better?
Software engineers don’t seem happier, nor do they seem to be paid more, nor do they seem to be being replaced by AI, nor do we have any examples of truly vibe coded software companies shipping incredible, beloved products.
In fact, I can’t think of a new piece of software I’ve used in the last few years that actually impressed me outside of Flighty.
Where’s the beef? What am I meant to be looking at? What’re you shipping that’s so impressive? Why should I give a shit?
Isn’t it weird that we’re even having this conversation? Shouldn’t it be obvious by now?
The Economics Of AI Are Weird And Bad, And It’s Even Weirder That People Try And Normalize Them
This week, economist Paul Kedrosky told me on the latest episode of my show Better Offline that AI is “...nowhere to be seen yet in any really meaningful productivity data anywhere,” and only appears in the non-residential fixed investments side of America’s GDP, at (and I quote again) “...levels we last saw with the railroad build out or with rural electrification.”
That’s so fucking weird! NVIDIA is the largest company on the US stock market and has sold hundreds of billions of dollars of GPUs in the last few years, with many of them sold to the Magnificent Seven, who are building massive data centers and reopening nuclear power plants to power them, and every single one of them is losing money doing so, with revenues so putrid they refuse to talk about them!
And all that to make…what, Gemini? To power ChatGPT and Claude? What does any of this actually do that makes any of those costs actually matter? And as I’ve discussed above, what, literally, does this software do that makes any of this worth it?
Ask the average AI booster — or even member of the media — and they’ll say something about “lots of code being written by AI,” or “novel discoveries” (unrelated to LLMs) or “LLMs finding new materials (based on an economics paper with faked data)” or “people doing research,” or, of course, “that these are the fastest-growing companies of all time.”
That “growth” is only possible because all of the companies in question heavily subsidize their products, spending $3 to $15 for every dollar of revenue. Even then, only OpenAI and Anthropic seem to be able to make “billions of dollars of revenue,” a statement that I put in quotes because however many billions there might be is up for discussion.
It’s Very Weird That The Media Ignored My Reporting on OpenAI’s Revenues, and Anthropic’s Statement That It Made $5 Billion In Revenue Through March 9, 2026
Back in November 2025, I reported that OpenAI had made — based on its revenue share with Microsoft — $4.329 billion between January and September 2025, despite The Information reporting that it had made $4.3 billion in the first half of the year based on disclosures to shareholders.
While a few outlets wrote it up, my reporting has been outright ignored by the rest of the media. I was not reached out to by or otherwise acknowledged by any other outlets, and every outlet has continued to repeat that OpenAI “made $13 billion in 2025,” despite that being very unlikely given that it would have required it to have made $8 billion in a single quarter. While I understand why — I’m an independent, after all — these numbers directly contradict existing reporting, which, if I was a reporter, would give me a great deal of concern about the validity of my reporting and the sources that had provided it.
Similarly, when Anthropic’s CFO said in a sworn affidavit that it had only made $5 billion in its entire existence, nobody seemed particularly bothered, despite reports saying it had made $4.5 billion in 2025, and multiple “annualized revenue” reports — including Anthropic’s own — that added up to over $6.6 billion.
Though I cannot say for certain, both of these situations suggest that Anthropic and OpenAI are misleading their investors, the media and the general public. If I were a reporter who had written about Anthropic or OpenAI’s revenues previously, I would be concerned that I had published something that wasn’t true, and even if I was certain that I was correct, I would have to consider the existence of information that ran counter to my own. I would be concerned that Anthropic or OpenAI had lied to me, or that they were lying to someone else, and work diligently to try and find out what happened. I would, at the very least, publish that there was conflicting information.
The S-1 will give us the truth, I guess.
It’s Weird That The Media Continues To Normalize OpenAI And Anthropic Losing Billions of Dollars
Does Anthropic Measure Its Gross Margins Based On How Much Revenue A Model Made Rather Than Revenue Minus COGS?
Let’s talk for a moment about margins, because they’re very important to measuring the length of a business.
Back in February in my Hater’s Guide To Anthropic, I raised concerns that Dario Amodei was using a different way to calculate margins than other companies do.
Amodei told the FT in December 2024 that he didn’t think profitability was based on how much you spent versus how much you made:
Let’s just take a hypothetical company. Let’s say you train a model in 2023. The model costs $100mn dollars. And, then, in 2024, that model generates, say, $300mn of revenue. Then, in 2024, you train the next model, which costs $1bn. And that model isn’t done yet, or it gets released near the end of 2024. Then, of course, it doesn’t generate revenue until 2025. So, if you ask “is the company profitable in 2024”, well, you made $300mn and you spent $1bn, so it doesn’t look profitable. If you ask, was each model profitable? Well, the 2023 model cost $100mn and generated several hundred million in revenue. So, the 2023 model is a profitable proposition.
He then did the same thing in an interview with John Collison in August 2025:
There's two different ways you could describe what's happening in the model business right now. So, let's say in 2023, you train a model that costs $100 million, and then you deploy it in 2024, and it makes $200 million of revenue. Meanwhile, because of the scaling laws, in 2024, you also train a model that costs $1 billion. And then in 2025, you get $2 billion of revenue from that $1 billion, and you've spent $10 billion to train the model.
So, if you look in a conventional way at the profit and loss of the company, you've lost $100 million the first year, you've lost $800 million the second year, and you've lost $8 billion in the third year, so it looks like it's getting worse and worse. If you consider each model to be a company, the model that was trained in 2023 was profitable. You paid $100 million, and then it made $200 million of revenue. There's some cost to inference with the model, but let's just assume, in this cartoonish cartoon example, that even if you add those two up, you're kind of in a good state. So, if every model was a company, the model, in this example, is actually profitable.
Almost exactly six months later on February 13, 2026’s appearance on the Dwarkesh Podcast, Dario would once again try and discuss profitability in terms other than “making more money than you’ve spent”:
Think about it this way. Again, these are stylized facts. These numbers are not exact. I’m just trying to make a toy model here. Let’s say half of your compute is for training and half of your compute is for inference. The inference has some gross margin that’s more than 50%.
So what that means is that if you were in steady-state, you build a data center and if you knew exactly the demand you were getting, you would get a certain amount of revenue. Let’s say you pay $100 billion a year for compute. On $50 billion a year you support $150 billion of revenue. The other $50 billion is used for training. Basically you’re profitable and you make $50 billion of profit. Those are the economics of the industry today, or not today but where we’re projecting forward in a year or two.
The only thing that makes that not the case is if you get less demand than $50 billion. Then you have more than 50% of your data center for research and you’re not profitable. So you train stronger models, but you’re not profitable. If you get more demand than you thought, then research gets squeezed, but you’re kind of able to support more inference and you’re more profitable.
The above quote has been used repeatedly to suggest that Anthropic has 50% gross margins and is “profitable,” which is extremely weird in and of itself as that’s not what Dario Amodei said at all. Based on The Information’s reporting from earlier in the year, Anthropic’s “gross margin” was 38%.”
Yet things have become even more confusing thanks to reporting from Eric Newcomer, who (in reporting on an investor presentation by Coatue from January) revealed that Anthropic’s gross margin was “45% in the quarter ended Sep-25,” with the crucial note that — and I quote — “Non-GAAP gross margins [are] calculated by Anthropic management…[are] unaudited, company-provided, and may not be comparable to other companies.”
This means that however Anthropic calculates its margins are not based on Generally Accepted Accounting Principles, which means that the real margins probably suck ass, because Anthropic loses billions of dollars a year, just like OpenAI.
Yet one seemingly-innocent line in there gives me even more pause: “Model payback improving significantly as revenue scales faster than R&D training costs.”
This directly matches with Dario Amodei’s bizarre idea that “...If you consider each model to be a company, the model that was trained in 2023 was profitable. You paid $100 million, and then it made $200 million of revenue.” Yes, I know it’s a “stylized fact” or whatever, but that’s what he said, and I think that their IPO might have a rude surprise in the form of a non-EBITDA margin calculation that makes even the most-ardent booster see red.
OpenAI and Anthropic Lose Billions of Dollars, But The Media Normalizes It In Any Way It Can, Acting As If Model Training Is Capex When It’s Actually A Cost of Goods Sold
This week, The Wall Street Journal published a piece about OpenAI and Anthropic's finances that included one of the most-offensive lines in tech media history:
Strip out “compute for research,” and OpenAI is actually on track to turn a small pretax operating profit this year, as is Anthropic under its best-case scenario. Add it back in, and OpenAI doesn’t expect to break even until the 2030s. Anthropic forecasts reaching that milestone sooner.
Two thoughts:
- Are you fucking kidding me? If you simply remove billions of dollars in costs, OpenAI is profitable!
- Why do you think these companies are going to break even anytime soon? You have absolutely no basis for doing so other than leaks from the company!
As I said a few months ago about training costs:
Yet arguably the most dishonest part is this word “training.” When you read “training,” you’re meant to think “oh, it’s training for something, this is an R&D cost,” when “training LLMs” is as consistent a cost as inference (the creation of the output) or any other kind of maintenance.
While most people know about pretraining — the shoving of large amounts of data into a model (this is a simplification I realize) — in reality a lot of the current spate of models use post-training, which covers everything from small tweaks to model behavior to full-blown reinforcement learning where experts reward or punish particular responses to prompts.
To be clear, all of this is well-known and documented, but the nomenclature of “training” suggests that it might stop one day, versus the truth: training costs are increasing dramatically, and “training” covers anything from training new models to bug fixes on existing ones. And, more fundamentally, it’s an ongoing cost — something that’s an essential and unavoidable cost of doing business.
The Journal also adds that both Anthropic and OpenAI are showing investors two versions of their earnings — one with training costs, and one without — without adding the commentary that this is extremely deceptive or, at the very least, extremely unusual.
The more I think about it the more frustrated I get. Having two sets of earnings is extremely dodgy! Especially when the difference between them is billions of dollars. This should be immediately concerning to every financial journalist, the reddest of red flags, the biggest sign that something weird is happening…
…but because this is the AI industry, the Journal runs propaganda instead:
Venture-capital firms have stomached vast losses in part because OpenAI and Anthropic are among the fastest-growing businesses in the history of tech. Each expects to more than double revenue this year, thanks largely to business customers’ adoption of new AI tools.
That “fast-growing” part is only possible because both Anthropic and OpenAI subsidize the compute of their subscribers, allowing them to burn $3 to $15 for every dollar of subscription revenue.
And no, this is nothing like Uber or Amazon, that’s a silly comparison, click that link and read what I said and then never bring it up again.
Anthropic’s Revenue Growth Is Weird and Suspicious — How Did It Go From $700 million in monthly revenue in December 2025 to $2.3 to $2.5 billion in April 2026?
I realize my suspicion around Anthropic’s growth has become something of a meme at this point, but I’m sorry, something is up here.
Let’s line it all up:
- Anthropic said on February 12, 2026 it had hit $14 billion in annualized revenue.
- This would work out to roughly $1.16 billion in a 30-day period, let’s assume from January 11 2026 to February 11 2026.
- Anthropic’s CFO said it had made “exceeding $5 billion” in lifetime revenue on March 9 2026.
- On March 3, 2026 Dario Amodei said it had hit $19 billion in annualized revenue.
- This would work out to $1.58 billion in a 30-day period.
- Let’s assume this is for the period from February 2 2026 to March 2 2026.
- On April 6, 2026, Anthropic said it had hit $30 billion in annualized revenue.
- This works out to about $2.5 billion in a 30-day period.
- Let’s assume that said period is March 6 2026 to April 6 2026.
Anthropic was making $9 billion in annualized revenue at the end of 2025, or approximately $750 million in a 30-day period.
Per Newcomer, as of December 2025, this is how Anthropic’s revenue breaks down:
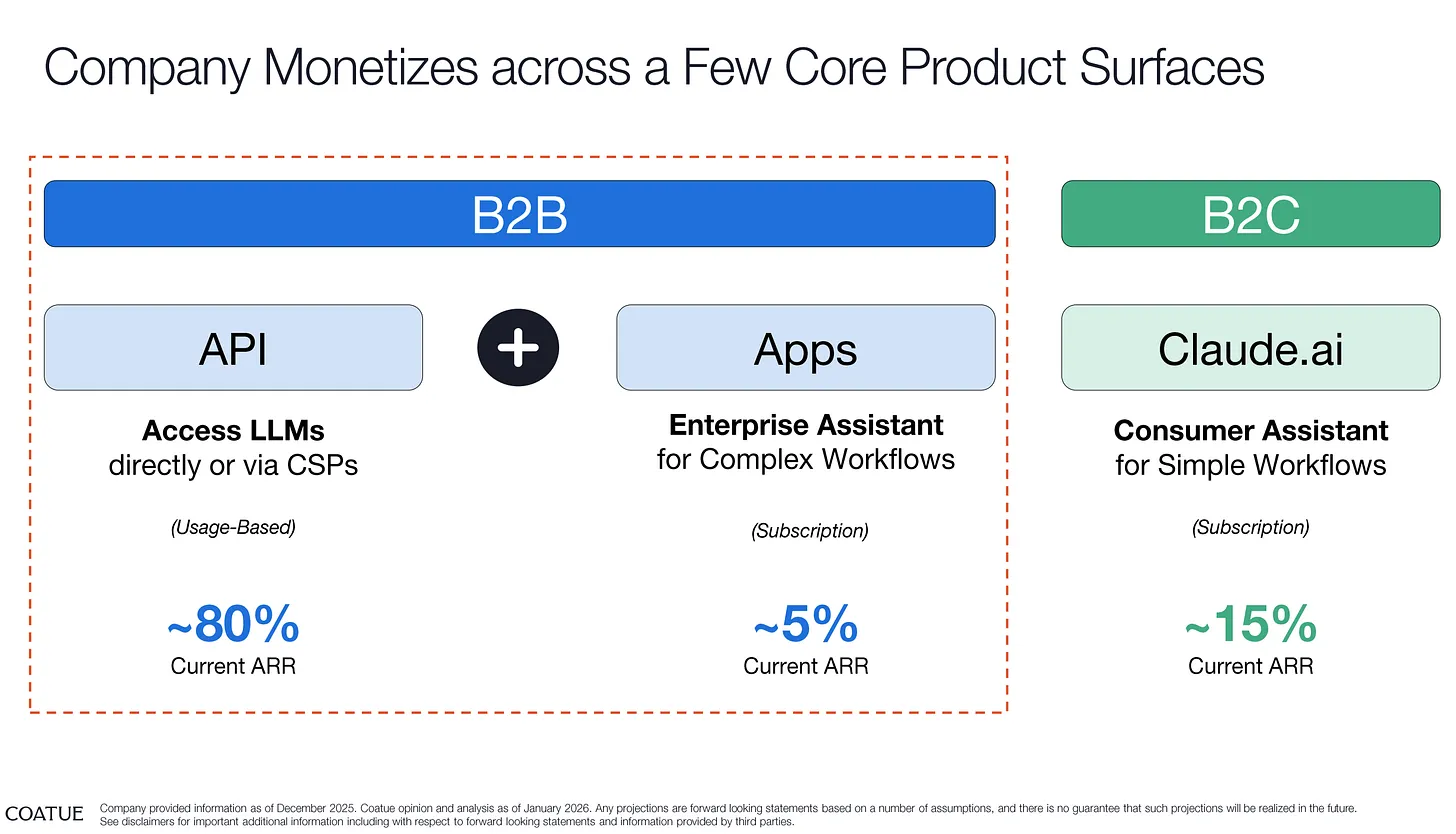
Per The Information, Anthropic also sells its models through Microsoft, Google and Amazon, and for whatever reason reports all of the revenue from their sales as its own and then takes out whatever cut it gives them as a sales and marketing expense:
Anthropic counts such revenue very differently from OpenAI. AWS, Microsoft and Google each resell Anthropic’s Claude models to their respective cloud customers, but Anthropic reports all those sales as revenue, before the cloud providers receive their share of those sales. Instead, Anthropic accounts for the cloud provider payouts in its sales and marketing expenses, as we’ve previously reported here.
The Information also adds that “...about 50% of Anthropic’s gross profits on selling its AI via Amazon has gone to Amazon,” and that “...Google typically takes a cut of somewhere between 20% and 30% of net revenue, after subtracting infrastructure costs.”
The problem here is that we don’t know what the actual amounts of revenue are that come from Amazon or Google (or Microsoft, for that matter, which started selling Anthropic’s models late last year), which makes it difficult to parse how much of a cut they’re getting. That being said, Google (per DataCenterDynamics/The Information) typically takes a cut of 20% to 30% of net revenue after subtracting the costs of serving the models.
Nevertheless, something is up with Anthropic’s revenue story.
Let’s humour Anthropic for a second and say that what it’s saying is completely true: it went from making $750 million in monthly revenue in January to $2.5 billion in monthly revenue in April 2026.
That’s remarkable growth, made even more remarkable by the fact that — based on its December breakdown — most of it appears to have come from API sales. That leap from $750 million to $1.16 billion between December and February feels, while ridiculous, not entirely impossible, but the further ratchet up to $2.5 billion is fucking weird!
But let’s try and work it out.
Anthropic’s Sonnet and Opus 4.6 Models Burn More Tokens Than Previous Models, and enable a 500% Larger 1 Million Token Context Window By Default, Artificially Inflating Costs For Similar Gains
On February 5 2026, Anthropic launched Opus 4.6, followed by Claude Sonnet 4.6 on February 17 2026.
Based on OpenRouter token burn rates, Opus 4.5 was burning around 370 billion tokens a week. Immediately on release, Opus 4.6 started burning way, way more tokens — 524 billion in its first week, then 643 billion, then 634 billion, then 771 billion, then 822 billion, then 976 billion, eventually going over a trillion tokens burned in the final week of March.
In the weeks approaching its successor’s launch, Sonnet 4.5 burned between 500 billion and 770 billion tokens. A week after launch, 4.6 burned 636 billion tokens, then 680 billion, then 890 billion, and, by about a month in, it had burned over a trillion tokens in a single week.
Reports across Reddit suggest that these new models burn far more tokens than their predecessors with questionable levels of improvement.
The sudden burst in token burn across OpenRouter doesn’t suggest a bunch of people suddenly decided to connect to Anthropic and other services’ models, but that the model themselves had started to burn nearly twice the amount of tokens to do the same tasks.
At this point, I estimate Anthropic’s revenue split to be more in the region of 75% API and 25% subscriptions, based on its supposed $2.5 billion in annualized revenue (out of $14 billion, so a little under 18%) in February coming from “Claude Code” (read: subscribers to Claude, there’s no “Claude Code” subscription).
If that’s the case, I truly have no idea how it could’ve possibly accelerated so aggressively, and as I’ve mentioned before, there is no way to reconcile having made $5 billion in lifetime revenue as of March 9, 2026, having $14 billion in annualized revenue on February 12 2026, and having $4.5 billion in revenue for the year 2025.
Things get more confusing when you hear how Anthropic calculates its annualized revenues, per The Information:
Anthropic calculates its annualized revenue by taking the last four weeks of application programming interface revenue and multiplying it by 13, and then adding another figure: its monthly recurring chatbot subscription revenue multiplied by 12, according to a person with direct knowledge of Anthropic’s finances. The monthly figure used to calculate recurring subscriptions is based on the number of active subscriptions that day, said the person.
So, Anthropic is annualizing based on the last four weeks of API revenue times 13, a number that’s extremely easy to manipulate using, say, launches of new products.
- Anthropic’s $14 billion in annualized revenue from February 16, 2026 includes both the launch of Claude Opus 4.6, as well as the height of the OpenClaw hype cycle where people were burning hundreds of dollars of tokens a day.
- This announcement also included the launch of Anthropic’s 1 million token context window in Beta for Opus 4.6
- Anthropic’s $19 billion in annualized revenue from March 3, 2026 included both the launch of Claude Opus 4.6 and Claude Sonnet 4.6.
- This period includes around half of the January 16 to February 16 2026 window from the previous $14 billion annualized number, and the launch of the beta of the 1 million token context window for Sonnet 4.6.
- To be clear, the betas required you to explicitly turn on the 1 million token context window, and had higher pricing around long context.
- Anthropic’s $30 billion in annualized revenue from April 6 2026 included two weeks’ worth of massive token burn from the launches of Sonnet and Opus 4.6.
- This includes a few days of the previous window (March 3 to April 5).
- This also included the general availability of the 1-million token context window, enabling it by default, billed at the standard pricing.
In simpler terms, Anthropic is cherry-picking four-week windows of API spend — ones that are pumped by big announcements and new model releases — and annualizing them.
Sidenote: I have no idea why Anthropic chose to multiply API revenue by 13, and only multiplied subscription revenue by 12. Multiplying by thirteen is perfectly reasonable when you’re using 28-day (or four week) windows, as if you multiply 28 by 12 and then subtract the result from 365, you’re left with 29. In essence, there’s thirteen four-week periods in a single calendar year.
But the discrepancy between API and subscription revenue? That’s weird.
The one million token context window is a big deal, too, having been raised from 200,000 tokens in previous models. With Opus and Sonnet 4.6, Anthropic lets users use up to one million tokens of context, which means that both models can now carry a very, very large conversation history, one that includes every single output, file, or, well, anything that was generated as a result of using the model via the API.
This leads to context bloat that absolutely rinses your token budget.
To explain, the context window is the information that the model can consider at once. With 4.6, Anthropic by default allows you to load in one million tokens’ worth of information at once, which means that every single prompt or action you take has the model load one million tokens’ worth of information at once unless you actively “trim” the window through context editing.
Let’s say you’re trying to work out a billing bug in a codebase via whatever interface you’re using to code with LLMs. You load in a 350,000 token codebase, a system prompt (IE: “you are a talented software engineer,” here’s an example), a few support tickets, and a bunch of word-heavy logs to try and fix it. On your first turn (question), you ask it to find the bug, and you send all of that information through. It spits out an answer, and then you ask it how to fix the bug…but “asking it to fix the bug” also re-sends everything, including the codebase, tickets and logs. As a result, you’re burning hundreds of thousands of tokens with every single prompt.
Although this is a simplified example, it’s the case across basically any coding product, such as Claude Code or Cursor. While Cursor uses codebase indexing to selectively fetch pieces of the codebase without constantly loading it into the context window, one developer using Claude inside of Cursor watched a single tool call burn 800,000 tokens by pulling an entire database into the context window, and I imagine others have run into similar problems. To be clear, Anthropic charges at a per-million-token rate of $5 per million input and $25 per million output, which means that those casually YOLOing entire codebases into context are burning shit tons of cash (or, in the case of subscribers, hitting their rate limits faster).
if Anthropic actually made $2.5 billion in a month — we’ll find out when it files its S-1! — it likely came not from genuine growth or a surge of adoption, but in its existing products suddenly costing a shit ton more because of how they’re engineered.
The other possibility is the nebulous form of “enterprise deals” that Anthropic allegedly has, and the theory that they somehow clustered in this three-month-long period, but that just feels too convenient.
If 70% of Anthropic’s revenue is truly from API calls, this would suggest:
- Massive new customers that are making payments up front, which makes this far from “recurring” revenue.
- Massive new customers are spending tons of money immediately, burning hundreds of millions of dollars a month in tokens, and paying Anthropic handsomely for them.
I don’t see much evidence of Anthropic creating custom integrations that actually matter, or — and fuck have I looked! — any real examples of businesses “doing stuff with Claude” other than making announcements about vague partnerships.
There’s also one other option: that Silicon Valley is effectively subsidizing Anthropic through an industry-wide token-burning psychosis.
And based on some recent news, there’s a chance that’s the case.
Does Meta’s “TokenMaxxing” Account For A Quarter of Anthropic’s Revenue?
As I discussed a few weeks ago, Silicon Valley has a “tokenmaxxing” problem, where engineers are encouraged by their companies to burn as many tokens as possible, at times by their peers, and at others by their companies.
The most egregious — and honestly, worrying! — version of this came from The Information’s recent story about Meta employees competing on an internal leaderboard to see who can burn the most tokens, deliberately increasing the size of their prompts and the amount of concurrent sessions (along with unfettered and dangerous OpenClaw usage) to do so:
The rankings, set up by a Meta employee on its intranet using company data, measure how many tokens—the units of data processed by AI models—employees are burning through. Dubbed “Claudeonomics” after the flagship product of AI startup Anthropic, the leaderboard aggregates AI usage from more than 85,000 Meta employees, listing the top 250 power users.
The practice is emblematic of Silicon Valley’s newest form of conspicuous consumption, known as “tokenmaxxing,” which has turned token usage into a benchmark for productivity and a competitive measure of who is most AI native. Workers are maximizing their prompts, coding sessions and the number of agents working in parallel to climb internal rankings at Meta and other companies and demonstrate their value as AI automates functions such as coding.
The Information reports that the dashboard, called “Claudeonomics” (despite said dashboard covering other models from OpenAI, Google, and xAI), has sparked competition within Meta, with users burning a remarkable 60 trillion tokens in the space of a month, with one individual averaging around 281 billion tokens, which The Information remarks could cost millions of dollars. Meta’s company-mandated psychosis also gives achievements for particular things like using multiple models or high utilization of the cache.
Here’s one very worrying anecdote:
Some workers are instructing AI agents to carry out research for hours on end to maximize their token usage, according to two current employees.
One poster on Twitter says that there are people at Meta running loops burning tokens to rise up the leaderboards, and that Meta’s managers also measure lines of code as a success metric.
The Information says that, considering Anthropic’s current pricing for its models, that 60 trillion tokens could be as much as $900 million in the space of a month, though adds that this assumes that every token being burned was on Claude Opus 4.6 (at $15 per 1 million tokens).
I personally think this maths is a bit fucked, because it assumes that A) everybody is only using Claude Opus, B) that none of that token burn runs through the cache (which it obviously does, and the cache charges 50%, as pointed out by OpenCode co-founder Dax Radd), and C) that Meta is entirely using the API (versus paying for a $200-a-month Claude Max subscription for each user).
Digging in further, it appears that a few years ago Meta created an internal coding tool called CodeCompose, though a source at Meta tells me that developers use VSCode and an assistant called Devmate connected to models from Anthropic, OpenAI and xAI.
One engineer on Reddit — albeit an anonymous one! — had some commentary on the subject:
We literally have a leaderboard of who has cost the most in compute. Not to share too much, but there are folks north of $80k in spend. Lmao. I’ve been really skeptical about the enterprise-level LLM push. It’s 100% an amazing tool, and I’ve been using Claude and tmux as my primary driver for ~six months, but it seemed like it maybe 2x’ed output, with a lot of time wasted in reinventing the wheel and bad naive solutions. The hype seemed like it was folks who had no idea what they were doing and who had never dealt with the complexities of a large codebase.
If we assume that Meta is an enterprise customer paying API rates for its tokens, it’s reasonable to assume — at even a low $5-per-million average — that it’s spending $300 million or more a month on API calls. As Radd also added, there’s likely a discount involved. He suggested 20%, which I agree with.
Even if it’s $300 million, that’s still fucking insane. That’s still over three billion dollars a year. If this is what’s actually happening, and this is what’s contributing to Anthropic’s growth, this is not a sustainable business model, which is par for the course for Anthropic, a company that has only lost billions of dollars.
Measuring Worker Output In Token Consumption Is Incredibly Weird, and TokenMaxxing Is Not A Sustainable Business Model
Encouraging workers to burn as many tokens as possible is incredibly irresponsible and antithetical to good business or software engineering. Writing great software is, in many cases, an exercise in efficiency and nuance, building something that runs well, is accessible and readable by future engineers working on it, and ideally uses as few resources as it can.
TokenMaxxing runs contrary to basically all good business and software practices, encouraging waste for the sake of waste, and resulting in little measurable productivity benefits or, in the case of Meta, anything user-facing that actually seems to have improved.
Venture capitalist Nick Davidov mentioned yesterday that sources at Google Cloud “started seeing billions of tokens per minute from Meta, which might now be as big as a quarter of all the token spend in Anthropic.” While I can’t verify this information (and Davidoff famously deleted his photos using Claude Cowork while attempting to reorganize his wife’s desktop), if that’s the case, Meta is a load-bearing pillar of Anthropic’s revenue — and, just as importantly, a large chunk of Anthropic’s revenue flows through Google Cloud, which means A) that Anthropic’s revenue truly hinges on Google selling its models, and B) that said revenue is heavily-inflated by the fact that Anthropic books revenue without cutting out Google’s 20%+ revenue share.
In any case, TokenMaxxing is not real demand, but an economic form of AI psychosis.
There is no rational reason to tell somebody to deliberately burn more resources without a defined output or outcome other than increasing how much of the resource is being used. I have confirmed with a source at that there is no actual metric or tracking of any return on investment involved in token burn at Meta, meaning that TokenMaxxing’s only purpose is to burn more tokens to go higher on a leaderboard, and is already creating bad habits across a company that already has decaying products and leadership.
To make matters worse, TokenMaxxing also teaches people to use Large Language Models poorly. While I think LLMs are massively-overrated and have their outcomes and potential massively overstated, anyone I know who actually uses them for coding generally has habits built around making sure token burn isn’t too ridiculous, and various ways to both do things faster without LLMs and ways to be intentional with the models you use for particular tasks. TokenMaxxing literally encourages you to do the opposite — to use whatever you want in whatever way you want to spend as much money as possible to do whatever you want because the only thing that matters is burning more tokens.
Furthermore, TokenMaxxing is exactly the kind of revenue that disappears first. Zuckerberg has reorganized his AI team four or five times already, and massively shifted Meta’s focus multiple times in the last five years, proving that at the very least he’ll move on a whim depending on external forces. After laying off tens of thousands of people in the last few years, Meta has shown it’s fully capable of dumping entire business lines or groups with a moment’s notice, and while moving on from AI might be embarrassing, that would suggest that Mark Zuckerberg experiences shame or any kind of emotion other than anger.
This is the kind of revenue that a business needs to treat with extreme caution, and if Meta is truly spending $300 million or more a month on tokens, Anthropic’s annualized revenues are aggressively and irresponsibly inflated to the point that they can’t be taken seriously, especially if said revenue travels through Google Cloud, which takes another 20% off the top at the very least.
TokenMaxxing Is A Valley-Wide Problem, Raising The Costs of Running Any Software Team Based On How AI-Crazed Your CEO Has Become — And When Cost Cuts Begin, API Revenue Will Collapse
Though the term is pretty new, the practice of encouraging your engineers to use AI as much as humanly possible is an industry-wide phenomena, especially across hyperscalers like Amazon, Microsoft and Google, all of whom until recently directly have pushed their workers to use models with few restraints. Shopify and other large companies are encouraging their workers to reflexively rely on AI, with performance reviews that include stats around your token burn and other nebulous “AI metrics” that don’t seem to connect to actual productivity.
I’m also hearing — though I’ve yet to be able to confirm it — that Anthropic and other model providers are forcing enterprise clients to start using the API directly rather than paying for monthly subscriptions.
Combined with mandates to “use as much AI as possible,” this naturally increases the cost of having software engineers, which — and I say this not wanting anyone to lose their jobs — does the literal opposite of replacing workers with AI. Instead, organizations are arbitrarily raising the cost of doing business without any real reason.
Because we’re still in the AI hype cycle, this kind of wasteful spending is both tolerated and encouraged, and the second that financial conditions worsen or stock prices drop due to increasing operating expenses, these same companies will cut back on API spend, which will overwhelmingly crush Anthropic’s glowing revenues.
The AI Bubble Is Weird, Irrational and Wasteful, And It’s Even Weirder That It’s A Fringe Opinion To Say So
I think it’s also worth asking at this point what is is we’re actually fucking doing.
We’re building — theoretically — hundreds of gigawatts of data centers, feeding hundreds of billions of dollars to NVIDIA to buy GPUs, all to build capacity for demand that doesn’t appear to exist, with only around $65 billion of revenue (not profit) for the entire generative AI industry in 2025, with much of that flowing from two companies (Anthropic and OpenAI) making money by offering their models to unprofitable AI startups that cannot survive without endless venture capital, which is also the case for both AI labs.
Said data centers make up 90% of NVIDIA’s revenue, which means that 8% or so of the S&P 500’s value comes from a company that makes money selling hardware to people that immediately lose money on installing it. That’s very weird! Even if you’re an AI booster, surely you want to know the truth, right?
The most-prominent companies in the AI industry — Anthropic and OpenAI — burn billions of dollars a year, have margins that get worse over time, and absolutely no path to profitability, yet the majority of the media act as if this is a problem that they will fix, even going as far as to make up rationalizations as to how they’ll fix it, focusing on big revenue numbers that wilt under scrutiny.
That’s extremely weird, and only made weirder by members of the media who seem to think it’s their job to defend AI companies’ bizarre and brittle businesses. It’s weird that the media’s default approach to AI has, for the most part, been to accept everything that the companies say, no matter how nonsensical it might be.
I mean, come on! It’s fucking weird that OpenAI plans to burn $121 billion in the next two years on compute for training its models, and that the media’s response is to say that somehow it will break even in 2030, even though there’s no actual explanation anywhere as to how that might happen other than vague statements about “efficiency.”
That’s weird! It’s really, really weird!
It’s also weird that we’re still having a debate about “the power of AI” and “what agents might do in the future” based on fantastical thoughts about “agents on the internet” that do not exist, cannot exist, and will never exist, and it’s fucking weird that executives and members of the media keep acting as if that’s the case. It’s also weird that people discussing agents don’t seem to want to discuss that OpenAI’s Operator Agent does not work, that AI browsers are fundamentally broken, or that agentic AI does not do anything that people discuss.
In fact, that’s one of the weirdest parts of the whole AI bubble: the possibility of something existing is enough for the media to cover it as if it exists, and a product saying that it will do something is enough for the media to believe it does it. It’s weird that somebody saying they will spend money is enough to make the media believe that something is actually happening, even if the company in question — say, Anthropic — literally can’t afford to pay for it.
It’s also weird how many outright lies are taking place, and how little the media seems to want to talk about them. Stargate was a lie! The whole time it was a lie! That time that Sam Altman and Masayoshi Son and Larry Ellison stood up at the white house and talked about a $500 billion infrastructure project was a lie! They never formed the entity! That’s so weird!
Hey, while I have you, isn’t it weird that OpenAI spent hundreds of millions of dollars to buy tech podcast TBPN “to help with comms and marketing”? It’s even weirder considering that TBPN was already a booster for OpenAI!
It’s also weird that a lot of AI data center projects don’t seem to actually exist, such as Nscale’s project to make “one of the most powerful AI computing centres ever” that is literally a pile of scaffolding, and that despite that announcement the company was able to raise $2 billion in funding.
It’s also weird that we’re all having to pretend that any of this matters. The revenues are terrible, Large Language Models are yet to provide any meaningful productivity improvements, and the only reason that they’ve been able to get as far as they have is a compliant media and a venture capital environment borne of a lack of anything else to invest in.
Coding LLMs are popular only because of their massive subsidies and corporate encouragement, and in the end will be seen as a useful-yet-incremental and way too expensive way to make the easy things easier and the harder things harder, all while filling codebases full of masses of unintentional, bloated code. If everybody was forced to pay their actual costs for LLM coding, I do not believe for a second that we’d have anywhere near the amount of mewling, submissive and desperate press around these models.
The AI bubble has every big, flashing warning sign you could ask for. Every company loses money. Seemingly every AI data center is behind schedule, and the vast majority of them aren’t even under construction. OpenAI’s CFO does not believe that it’s ready to go public in 2026, and Sam Altman’s reaction has been to have her report to somebody else other than him, the CEO. Both OpenAI and Anthropic’s margins are worse than they projected. Every AI startup has to raise hundreds of millions of dollars, and their products are so weak that they can only make millions of dollars of revenue after subsidizing the underlying cost of goods to the point of mass unprofitability.
And it’s really weird that the mainstream media has a diametric view — that all of this is totally permissible under the auspices of hypergrowth, that these companies will simply grow larger, that they will somehow become profitable in a way that nobody can actually describe, that demand for AI data centers will exist despite there being no signs of that happening.
I get it. Living in my world is weird in and of itself. If you think like I do, you have to see every announcement by Anthropic or OpenAI as suspicious — which should be the default position of every journalist, but I digress — and any promise of spending billions of dollars as impossible without infinite resources.
At the end of this era, I think we’re all going to have to have a conversation about the innate credulity of the business and tech media, and how often that was co-opted to help the rich get richer.
Until then, can we at least admit how weird this all is?
