
Hello premium subs! This is your ad-free free newsletter for the week. Questions? Queries? Email me at ez@betteroffline.com, and if you have a scoop, ezitron.76 is my Signal.
Yesterday morning, GitHub Copilot users got confirmation of something I’d reported a week ago — that all GitHub Copilot plans would move to usage-based pricing on June 1, 2026.
Instead of offering users a certain number of “requests,” Microsoft will now charge users based on the actual cost of the models they’re using, which it calls “...an important step toward a sustainable, reliable Copilot business and experience for all users.” Users instead get however much they spend on their GitHub Copilot subscription (EG: $19 of tokens a month on a $19-a-month plan).
Translation: "we cannot continue to subsidize GitHub Copilot users, or Amy Hood will start hitting people with a baseball bat."
Anyway, the announcement itself was a fascinating preview into how these price changes are going to get framed:
Copilot is not the same product it was a year ago.
It has evolved from an in-editor assistant into an agentic platform capable of running long, multi-step coding sessions, using the latest models, and iterating across entire repositories. Agentic usage is becoming the default, and it brings significantly higher compute and inference demands.
Today, a quick chat question and a multi-hour autonomous coding session can cost the user the same amount. GitHub has absorbed much of the escalating inference cost behind that usage, but the current premium request model is no longer sustainable.
Usage-based billing fixes that. It better aligns pricing with actual usage, helps us maintain long-term service reliability, and reduces the need to gate heavy users.
You see, it’s not that Microsoft was subsidizing nearly two million people’s compute, it’s that AI has become so strong, powerful and complex that it’s basically a different product!
While Copilot might not be “...the same product it was a year ago,” very little has changed about the underlying economic mismatch: that Microsoft was allowing users to burn more than their subscription costs in tokens every single month for three years. Per the Wall Street Journal in October 2023:
Individuals pay $10 a month for the AI assistant. In the first few months of this year, the company was losing on average more than $20 a month per user, according to a person familiar with the figures, who said some users were costing the company as much as $80 a month.
Naturally, GitHub Copilot users are in revolt, saying that the product is “dead” and “completely ruined.”
And I called it two years ago in the Subprime AI Crisis:
I hypothesize a kind of subprime AI crisis is brewing, where almost the entire tech industry has bought in on a technology sold at a vastly-discounted rate, heavily-centralized and subsidized by big tech. At some point, the incredible, toxic burn-rate of generative AI is going to catch up with them, which in turn will lead to price increases, or companies releasing new products and features with wildly onerous rates — like the egregious $2-a-conversation rate for Salesforce’s “Agentforce” product — that will make even stalwart enterprise customers with budget to burn unable to justify the expense.
And that day has finally arrived, because every single AI service you use subsidized compute, and every single service is losing money as a result:
When you pay for access to an AI startup’s service — which, of course, includes OpenAI and Anthropic — you do so for a monthly fee, such as $20, $100 or $200-a-month in the case of Anthropic’s Claude, Perplexity’s $20 or $200-a-month plan, or OpenAI’s $8, $20, or $200-a-month subscriptions. In some enterprise use cases, you’re given “credits” for certain units of work, such as how Lovable allows users “100 monthly credits” in its $25-a-month subscription, as well as $25 (until the end of Q1 2026) of cloud hosting, with rollovers of credits between months.
When you use these services, the company in question then pays for access to the AI models in question, either at a per-million-token rate to an AI lab, or (in the case of Anthropic and OpenAI) whatever cloud provider is renting them the GPUs to run the models. A token is basically ¾ of a word.
As a user, you do not experience token burn, just the process of inputs and outputs. AI labs obfuscate the cost of services by using “tokens” or “messages” or 5-hour-rate limits with percentage gauges, and you, as the user, do not really know how much any of it costs. On the back end, AI startups are annihilating cash, with up until recently Anthropic allowing you to burn upwards of $8 in compute for every dollar of your subscription. OpenAI allows you to do the same, though it’s hard to gauge by how much.
AI startups and hyperscalers assumed that they’d be able to get enough people through the door with subsidized, loss-making products to get them hooked on services badly enough that they’d refuse to change once businesses jacked up the prices. They also assumed, I imagine, that the cost of tokens would come down over time, versus what actually happened — while prices for some models might have come down, newer “reasoning” models burn way more tokens, which means the cost of inference has, somehow, gotten higher over time.
Both assumptions were wrong, because the monthly subscription model does not make sense for any service connected to a Large Language Model.
The Core Economics of Generative AI Are Broken
Think of it like this. When Uber (and no, this is nothing like Uber) started jacking up the prices for its rides, the underlying economics stayed the same, as did those presented to both the rider and the driver — a user paid for a ride, a driver was paid for a ride. Drivers still paid for gas, car insurance, any permits that their local government might insist upon, and whatever financing costs might be associated with their vehicle, and said costs were not subsidized by Uber. Uber’s massive losses came from subsidies, endless marketing expenses, and doomed R&D efforts into things like driverless cars .
Generative AI Subscriptions Are Nothing Like Uber
To illustrate the scale of AI’s pricing mismatch, I’m going to ask you to imagine an alternate history where Uber had a very different business model.
Generative AI subscriptions are like if Uber charged users $20 a month for 100 rides of any distance under 100 miles, and if gas was $150 a gallon, and Uber paid for the gas because somebody insisted that oil would one day be too cheap to meter.
Uber would, eventually, decide to start charging users a monthly subscription to access rides, and bill them for the gas that they consumed. Suddenly users would go from paying $20 a month for 100 rides to paying $20 to access a driver and $26 for a 10 mile drive. Understandably, users would be a little upset.
While this sounds a little dramatic, it’s actually a pretty accurate metaphor for what’s happening in the generative AI industry, and in particular, at Github Copilot.
GitHub Copilot’s previous pricing allowed 300 premium requests a month, as well as “unlimited chat requests” using models like GPT-5 mini. Each of these requests (to quote Microsoft) is “...any interaction where you ask Copilot to do something for you,” with more-expensive models taking up more requests in the later life of the request-based system, such as Claude Opus 4.6 taking up three premium requests. When you ran out of premium requests, Copilot would let you use one of those cheaper models as much as you’d like for the rest of the month.
This wasn’t even always the case. Up until May 2025, Microsoft gave users unlimited access to models, and even then users were pissed off that there were any restrictions on the product.
Microsoft — like every AI company — swindled its customers by selling an unsustainable service, because it never, ever made sense to sell LLM-powered services on a monthly subscription.
If you’re wondering how much services are likely to cost under token based billing, a user on the GitHub Copilot Subreddit found that the token burn of what used to be a single premium request was somewhere around $11, as one “request” involved using 60,000 tokens in the context window, a few tools, and a bunch of internal “turns” (things that the model is doing) to produce the output.
There’s also the underlying unreliability of hallucination-prone Large Language Models. While a premium request chasing its tail and spitting out half-broken code might be frustrating, that same fuckup is a lot less forgivable when you’re paying the costs yourself.
Users have also been trained to use the product in an entirely different manner to token-based billing, and I’d imagine many of them don’t even really realize how many “tokens” they burn or how many of them a particular task takes, something which changes based on whatever model you use.
This is absolutely nothing like Uber, and anyone telling you otherwise is attempting to rationalize bad behavior. Uber may have raised prices, but it didn’t have to dramatically change the underlying economics of the platform, nor did users have to entirely change how they used the product because Uber was suddenly charging them on a per-gallon basis.
Monthly AI Subscriptions Are All Part of AI’s Subsidy Scam, A Deliberate Attempt To Separate Generative AI From Its Actual Costs
There has never been — and never will be — an economically-feasible way to offer services powered by LLMs without charging the actual token burn of each user, and in the process of deceiving said users, these companies have created products with illusory benefits and questionable return on investment.
And that’s been blatantly obvious for years.
On an economic basis, a monthly subscription only makes sense with relatively static costs. A gym can sell memberships knowing roughly how much wear-and-tear equipment gets, how much classes cost to run, and how much things like electricity, staffing and water might cost over a given period of time.
A customer of Google Workspace — at least before AI — cost whatever the cost of accessing or storing documents were, as well as the ongoing costs of Google Docs and other services. The relatively low cost of digital storage (as well as the fact that, unlike LLMs, Google Workspace isn’t particularly computationally demanding) means that a particularly-heavy Google Drive user isn’t going to eat into the margin on their monthly subscription.
Conversely, an AI subscriber’s costs can vary wildly. One user might only use ChatGPT for the occasional search, while another might feed in reams of documents, or try and refactor a codebase, or try and use it to put together a PowerPoint presentation. And the provider — a model lab like OpenAI or Anthropic, or a startup like Cursor) — has no real way to control how a user might act other than making the product worse, such as instituting usage limits, reducing the size of the context window, pushing customers to smaller (and worse) models, or changing the pricing to dissuage users from making big GPU-heavy requests.
Yet these services intentionally hide the amount of tokens or how much a particular activity has cost, which means users don’t really know what a rate limit means, which means that every abrupt change to rate limits leaves customers desperately scrambling to work out how much actual work they can do using the service.
It’s an abusive, manipulative and deceitful way of doing business that only existed so that Anthropic, OpenAI, and other AI companies could grow their user bases, as the majority of AI users perceive its real or imagined benefits entirely through the lens of being able to burn anywhere from $8 to $13.50 for every dollar of their subscription in tokens.
This intentional act of deception had one goal: to make sure that the majority of people were never exposed to the true costs of generative AI. When The Atlantic writes a breathless screed about Claude Code being Anthropic’s “ChatGPT moment,” it does so based on a $20-a-month subscription rather than the underlying token burn that it cost for Anthropic to provide it, which in turn makes the writer forgive the “minor errors” that a model might make, or when it “gets stuck on more complicated programming tasks.”
Had the writer paid for her actual token burn, and had each of the times it got “stuck” resulted in $15 in token charges, I don’t think she’d be quite as forgiving of these fuckups.
Yet that’s all part of the scam.
It’s very, very important that nobody writing about AI in the mainstream media actually understands how much these services cost, and that any mainstream articles written about services like ChatGPT or Claude Code are written by people who have little or no idea how much each individual task might cost a user.
Remember: generative AI services are, for the most part, experimental products that do not function like any other modern software or hardware. One cannot just walk up to ChatGPT or Claude and start asking it to do work.
I mean, you can, but if you don’t prompt it right, understand how it works, or make a mistake in whatever you feed it, or if it just gets things wrong, it’ll spit out something you don’t like, which in turn means you’ll need to prompt it again. LLMs are inherently unpredictable.
You cannot guarantee whether an LLM will do a particular action, or whether it will present you with an outcome based on reality. You cannot for certain say how much a particular task — even one you’ve done many times using an LLM in the past — might cost, nor can you be sure when a model might go berserk and delete something, or simply not do something yet claim that it did.
These are far more forgivable if you’ve not paying on a per-token basis, because in the mind of a subscriber, that’s just another turn or two with a chatbot rather than something that’s incurring a real cost. One doesn’t criticize so-called “jagged intelligence” because the assumption is that whatever problems you’re facing now will be eliminated at some future juncture, and you didn’t end up paying for it anyway.
Had users been forced to pay their actual rates, I imagine many would’ve bounced off the product immediately, as it’s very, very easy to burn through $5 of tokens if you’re fucking around and exploring what an LLM can do.
Sidenote: In fact, you can burn a great deal of money without ever getting the outcome you desire, because LLMs aren’t really artificial intelligence at all! Somebody without any real understanding of their limitations could easily burn $30, or $50, or even $100 trying to convince an LLM to do something it insists it’s capable of.
There’s a term for this. Sycophancy. LLMs are often designed to affirm the user, even when they’re saying dangerously unhinged things, and that can extend to saying “you want this big thing that’s not even slightly feasible, whether technically or financially?” Sure thing!
This is why the industry worked so hard to obfuscate these costs — it’s a fucking ripoff!
I think it’s inevitable that the majority of AI subscriptions move to token-based billing, especially as both Anthropic and OpenAI have now done so with their enterprise customers.
The fact that Microsoft moved GitHub Copilot subscribers to token-based is also a very, very bad sign. Microsoft is arguably the best-capitalized, most-profitable, and best-positioned company to continue subsidizing compute, and if it can’t afford to do so further, nobody else can either.
The real thing to look out for — a true pale horse — will be a major AI lab like Anthropic or OpenAI moving all of its subscribers to token-based billing. Once that happens, you’ll know it’s closing time.
Can The Average Company Afford To Move To Token-Based Billing? Anthropic Estimates Users Spend $13-$30 a day ($7K+ a year) On Claude Code, As Large Organizations Spend Hundreds of Thousands or Millions A Year
As I discussed last week, Uber’s CTO said at a conference that it had spent its entire AI budget for 2026 in the space of a few months, with Goldman Sachs suggesting that some companies are spending as much as 10% of their headcount on AI tokens, with the potential to increase to 100% in the next few quarters.
This is the direct result of training every single AI user to use these services as much as humanely possible while obfuscating how much they really cost. Every single major company demanding that every single worker “use AI as much as possible” has done so while either fundamentally ignoring or being entirely disconnected from their actual token burn, and as companies are forced to pay the actual costs, I’m not sure how you can economically justify any investment in this technology.
Sure, sure, you’re gonna say that engineers are “shipping code faster” or some such bullshit, I get it, but how much faster, and how much money are you making or saving as a result? If you’re spending 10% of your headcount on AI tokens, are you seeing that extra expense reconciled in some other way? Because I’m not sure you are. I’m not sure any business investing these vast amounts of money in tokens is seeing any return on investment, which is why every study about AI’s ROI struggles to find much evidence that it exists.
For the most part, everybody you’ve read gooning over the many possibilities of generative AI has experienced it without having to pay the true costs. Every Twitter psychopath writing endless screeds about their entire engineering team hammering away at Claude Code has been doing so using a $125-a-month-per-head Teams subscription with similar usage limits to Anthropic’s $100-a-month consumer subscription. Every LinkedIn gargoyle insisting that they’d “done hours of work in minutes” using some sort of Perplexity product has done so by paying, at the very most, $200 a month for Perplexity’s Max subscription.
In reality, that 10-person, $1250-a-month Teams subscription likely burns anywhere from $5000 to $10,000 a month in API calls, if not more. Anthropic Head of Growth Amol Avasare said last week that its Max subscriptions were built for heavy chat usage rather than whatever people are doing with Claude Code and Cowork, and made it clear that Anthropic is now looking at “different options to keep delivering a great experience,” which is another way of saying “we’re going to change the prices at some point.”
I’m not sure people realize how expensive these tokens are, especially for coding projects that involve massive codebases and regularly make calls to coding and infrastructure tools. Can somebody who pays $200 a month foreseeably afford $350, $400, or $500? Can they afford to have a month where they spend more than that? What happens if they go over budget, or if they literally can’t afford to spend the money necessary to finish their work?
To give you a more-practical example, up until the beginning of April, Anthropic’s own Claude Code developer documents (archive) said that “the average cost [for those using Claude Code] is $6 per developer per day, with daily costs remaining below $12 for 90% of users.” As of this week, the documents now read as follows:
Claude Code charges by API token consumption. For subscription plan pricing (Pro, Max, Team, Enterprise), see claude.com/pricing. Per-developer costs vary widely based on model selection, codebase size, and usage patterns such as running multiple instances or automation.
Across enterprise deployments, the average cost is around $13 per developer per active day and $150-250 per developer per month, with costs remaining below $30 per active day for 90% of users. To estimate spend for your own team, start with a small pilot group and use the tracking tools below to establish a baseline before wider rollout.
If we assume an average of 21 working days in a month, that puts the average cost of a Claude Code user at around $273 a month, or $3,276 a year. At $30 a working day, that works out to $630 a month, or $7560 a year.
These are astonishing numbers, made more so by the fact that there is no way you’re only spending $30 a day if you use any of Anthropic’s more-recent models. Claude Opus 4.7 costs $5 per million input and $25 per million output tokens. ‘One million tokens is around 50,000 lines of code, and assuming you’re using the supposedly state-of-the-art models, there isn’t a chance in Hell you don’t run through at least a million, with that number increasing dramatically if you’re not particularly aware of which models to use for a particular task.
Let’s play with that $30 number a little more.
- For a ten person dev team, that’s $75,600 a year, and we’re only counting working days.
- If you raise a mere three months to an average of $50 a working day, that raises to $88,200
- If you add a single month where you go over $100, you’re spending $102,900 a year.
- If you spend $300 a day, you’re now spending $756,000 on tokens for ten people.
While this might be possible within the slush fund mindset of a well-funded startup or a banana republic like Meta, any business that actually cares about its costs will have a great deal of trouble justifying spending five or six figures in extra costs on a service that “increases productivity” in a way that nobody can seem to measure.
Right now, I think most companies fall into three camps:
- Enterprise deployments in massive organizations like Spotify or Uber with AI-pilled CEOs that allow budgets to run wild.
- I’d also say this is the case in large, well-funded startups.
- Smaller startups that use the subsidized “Teams” subscription.
- Individual users paying a monthly fee to access Claude or other AI subscriptions.
Large organizations still have a free pass to say that they’re burning millions of dollars on AI tokens for their software engineers under the questionable benefit of their “best engineers” not writing any code.
All it changes is one bad earnings call to change that narrative. At some point investors — even the braindead fuckwits who have been inflating the AI bubble — will begin to question mounting R&D costs (which is where AI token burn is usually hidden) when the company’s revenue growth fails to follow. This will likely lead to more layoffs to keep up with the cost, as was the case with Meta, and then an eventual pullback when somebody asks “does any of this shit actually help us do our jobs faster or better?”
I also think that startups burning 10% or more of their headcount in AI tokens will have a tough time convincing investors in six months that doing so is necessary.
And once everybody switches to token-based billing, I’m not sure we’ll see quite as much hype around generative AI.
The Economics of AI Data Centers And Compute Do Not Make Sense
The way that people talk about AI data centers is completely disconnected from reality, and I don’t think people realize how ridiculous this entire era has become.
AI Data Centers Are Expensive To Build, Expensive To Run and Make Very Little Actual Revenue
Per Jerome Darling of TD Cowen, it costs around $30 million in critical IT (GPUs and the associated hardware) and $14 million per megawatt of data center capacity. Data centers appear to take anywhere from a year to three years depending on the size, and that’s assuming the power is available.
Of the 114GW of data centers supposedly being built by the end of 2028, only 15.2GW is under construction in any way, shape, or form. And “under construction” can mean as little as “there’s a hole in the ground.” It does not — and should not — imply that the capacity that said facility will provide is going to be imminently available.
Sidebar: If you’re interested in some of the deeper math here, please subscribe to my premium newsletter so that you can see my Bastard Data Center Model, which I created with the assistance of multiple analysts and hyperscaler sources.
Let’s start simple: whenever you think “100MW,” think “$4.4 billion,” with a large chunk of that dedicated to NVIDIA GPUs.
As a result, every AI data center starts millions of dollars in the hole, and even with six-year-long depreciation schedules, takes years to pay off… and with NVIDIA’s yearly upgrade cycle, those GPUs are unlikely to make that much money once you’re done with your first customer contract.
It’s also unclear whether the customer base for AI compute exists outside of OpenAI and Anthropic, whose demand accounts for 50% of AI data centers under construction, creating a massive systemic weakness if either of them lacks the money to pay.
In any case, it’s also unclear what kind of ongoing rates these data centers charge. While spot prices might sit around $4.50 an hour for a B200 GPU, long-term contracts generally price much lower, with one founder (per The Information) saying they paid around $3.70-per-hour-per GPU for a one-year-long commitment.
To be clear, we must differentiate between the spot cost — which is the cost of randomly spinning up GPUs on somebody else’s servers — and contracted compute, the latter of which makes up the majority of data center capex. Most data centers are built with the intention of having one or two big clients, which means said clients are likely to negotiate a cheaper blended rate.
As a result, many data centers take far less than $3.70 an hour, because they bill at a per-megawatt (or kilowatt) price.
And that’s where the economics begin to break down.
The Broken Economics of a 100MW Data center — $2.55 An Hour, 16% Gross Margin With 100% Tenancy, Unprofitable Because of Debt
That’s the starting cost for a 100 megawatt data center. A 100MW data center will likely only have 85MW of actual stuff it can bill for, and based on discussions with sources familiar with hyperscaler billing, they can expect to make around $12.5 million per megawatt, or around $1.063 billion in annual revenue.
Now, I should be clear that most data center companies you know of don’t actually build them, instead leaving that job to companies like Applied Digital, who are also known as “colocation partners.” For example, CoreWeave pays a colocation fee to Applied Digital to use its North Dakota data centers. CoreWeave is responsible for all the GPUs and other tech inside the data center.
To explain the economic mismatch, I’m going to use a theoretical example of a data center leased to a theoretical AI compute company.
The GPUs in that data center are likely NVIDIA’s Blackwell chips. More than likely, said data center is using pods of 8 B200 GPUs, retailing around $450,000 a piece, or $56,250 a GPU. Based on there being 85MW of Critical IT load, the all-in capex per megawatt is around $36.78, or total IT capex of around $3.126 billion, or around $2.67 billion in GPUs.
Let’s assume this data center is in Ellendale, North Dakota, which means you’ve got an industrial electricity rate of around 6.31 cents per kilowatt hour, which works out to about $55.4 million a year in electricity costs. Based on discussions with sources, I estimate that ongoing costs like maintenance, headcount, replacement of power supplies and the like comes in at around 12% of revenue, or around $128 million a year, bringing us up to $183.4 million in costs.
Wait, sorry. You’ve also got to pay a colocation fee based on the critical IT, and according to Brightlio, that fee is often around $180-200 per kilowatt per month, depending on the scale and location of the deployment, though I’ve read as low as $130, which is the number I’m going with, or around $133 million per year. This brings us up to $316.4 million.
Well, that’s still less than $1.06 billion, so we’re still doing okay, right?
Wrong! You’ve got $3.126 billion in IT gear to depreciate, which works out to around $521 million a year over the six years you’re depreciating it. That’s $837.4 million a year, leaving you with around $168.6 million in yearly profit, or around a 16.7% gross margin…
…if you have 100% tenancy at all times! You see, data centers can take a month or two to get those GPUs installed and a customer onboarded, all while making you exactly zero dollars in revenue and losing you a great deal more, as you’re stuck paying your colocation, electricity and opex costs the whole time, albeit at a much lower rate (I’ve modeled for 10% electricity and 15% colocation/opex costs), meaning you’re losing about $3.27 million a day.
For the sake of this example, we’re going to assume it takes you an extra month to get this thing operational, meaning you’ve paid about $102 million that you’re never getting back, bringing our total costs for the year including depreciation to $939.4 million, or a 6.6% gross margin.
Wait, fuck, you didn’t use debt to buy these GPUs, did you? You did? How bad are we talking? Oh god — you got a 6-year-long asset-backed loan at 80% LTV, meaning you borrowed $2.8 billion at a 6% interest rate.
Your bank, in its eternal generosity, offered you a deal — a 12-month-long grace period where you’re only paying interest…which works out to around $168 million, which brings our total costs (excluding the month of delay for fairness) for the first year to around $1.005 billion…on $1.06 billion of revenue.
That’s a 5.19% gross margin, and you haven’t even started paying the principal. When that happens, you’re paying $54.1 million a month in loan payments, for a total of around $649 million a year for five more years, which comes out to around $1.48 billion, or a negative gross margin of around 40%.
And I must be clear that this is if you have 100% utilization and a tenant that pays you on time, every time.
Stargate Abilene Is A Disaster — $2.94-per-GPU-per-hour, $10 Billion In Annual Revenue, Years Behind Schedule, One Tenant That Loses Billions of Dollars A Year
Let’s talk about what should be the single-most economically viable project in data center history — a massive campus built for the largest AI company in the world by Oracle, a decades-old near-hyperscaler with a history of selling expensive database and business management software to enterprises and governments.
Hah, I’m kidding of course, this place is a fucking nightmare.
Stargate Abilene, an eight-building, 1.2GW data center campus with around 824MW of critical IT, was first announced in July 2024. As of April 27 2026, only two buildings are operational and generating revenue, and the third barely has any IT gear in it. I estimate the total cost of Stargate Abilene to be around $52.8 billion.
Per my own reporting, Oracle expects to make around $10 billion in annual revenue from Stargate Abilene, and I estimate around $75 billion in total revenue from the 7.1GW of data center capacity it’s building for one customer: OpenAI. As I also reported, Oracle estimated in 2024 that Abilene would cost at least $2.14 billion a year in colocation and electricity fees, paid to land developer Crusoe.
I should also add that it appears that Oracle is paying all of Abilene’s construction costs.
Based on my calculations and reporting, I estimate Abilene’s rough gross margin is around 37.47% once it’s fully operational:
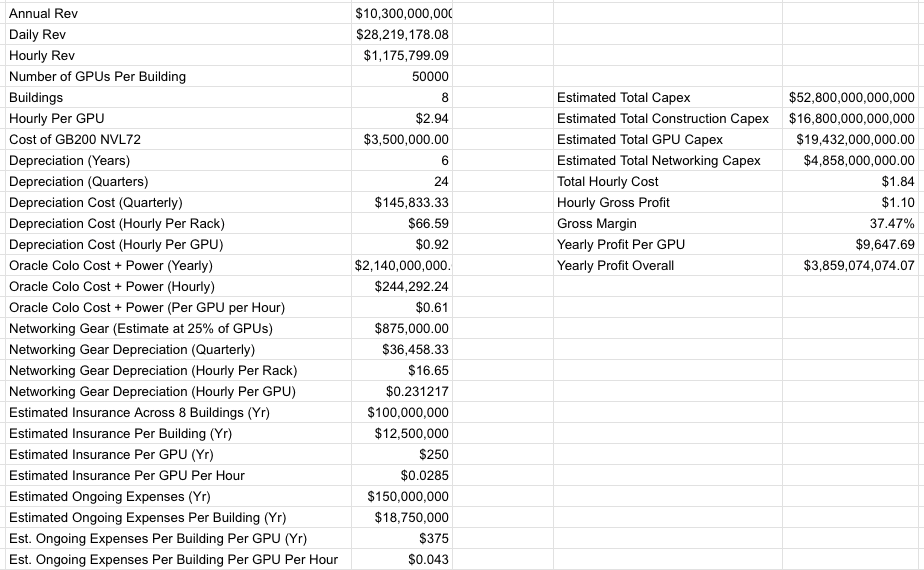
I must be clear that that 37.47% gross margin is likely too high, as I don’t have precise knowledge of Oracle’s true insurance or headcount costs, only estimates based on documents viewed by this publication. I should also be clear that Oracle is mortgaging its entire fucking future on projects like Stargate Abilene, incurring billions of dollars of costs up front for a business that will take years to turn a profit even if OpenAI makes every single payment in a timely manner.
Sadly, I can’t tell how much of Abilene was paid for in debt, only that Oracle raised around $18 billion in various-sized bonds in September 2025, with maturities ranging from 7 years to 40 years, and had negative cashflow of $24.7 billion in its last quarterly earnings.
What I do know is that it has a 15-year-long lease with developer Crusoe, and that Oracle’s future heavily depends on OpenAI’s continued ability to pay, which depends on Oracle’s ability to finish Stargate Abilene.
I also need to be clear that that $3.85 billion in yearly profit is only possible if OpenAI makes timely payments, takes tenancy of Abilene as fast as humanly possible, and everything goes to plan.
If OpenAI Fails To Raise $852 Billion In Revenue, Funding, and Debt Throughout The Next 4 Years, The Stargate Data Center Project Will Kill Oracle
Sadly, the complete opposite has happened:
Based on reporting from DatacenterDynamics, the first 200MW of power was meant to be energized “in 2025.” As time dragged on, occupancy was meant to begin in the first half of 2025, had “potential to reach 1GW by 2025,” complete all 1.2GW of capacity by mid-2026, be energized by mid-2026, have 64,000 GPUs by the end of 2026, as of September 30, 2025 had “two buildings live,” and as of December 12, 2025, Oracle co-CEO Clay Magouyurk said that Abilene was “on track” with “more than 96,000 NVIDIA Grace Blackwell GB200 delivered,” otherwise known as two buildings’ worth of GPUs.
Four months later on April 22, 2026, Oracle tweeted that “...in Abilene, 200MW is already operational, and delivery of the eight-building campus remains on schedule.” It is unclear if that’s 200MW of critical IT capacity or the total available power at the Abilene campus, and in any case, this is only enough power for two buildings, which means that Oracle is most decidedly not “on schedule.”
This is a huge issue. OpenAI can only pay for compute that actually exists, and only 206MW of critical IT is actually generating revenue, with the third at least a month (if not a quarter) away from doing so.
Yet there’s a larger, more-existential problem with the overall Stargate data center project — that the only way any of it makes sense is if OpenAI meets its ridiculous, cartoonish projections.
I’ll repeat the numbers: the 7.1GW of Stargate data centers in progress will make around $75 billion in annual revenue on completion, and cost more than $340 billion in total. Oracle’s free cash flow was negative $24.7 billion, and its other business lines are plateauing, making its negative-to-low margin cloud business its only growth engine.
For OpenAI to actually be able to pay its compute deals — both to partners like Amazon, Microsoft, CoreWeave, Google, Cerberas, and to Oracle — it will have to raise or make $852 billion in revenue and/or funding in the space of four years, which would require its business to grow by more than 250%, every single year, effectively 10xing by the end of 2030, at which point it will have had to find a way to become cashflow positive for any of these numbers to make sense.
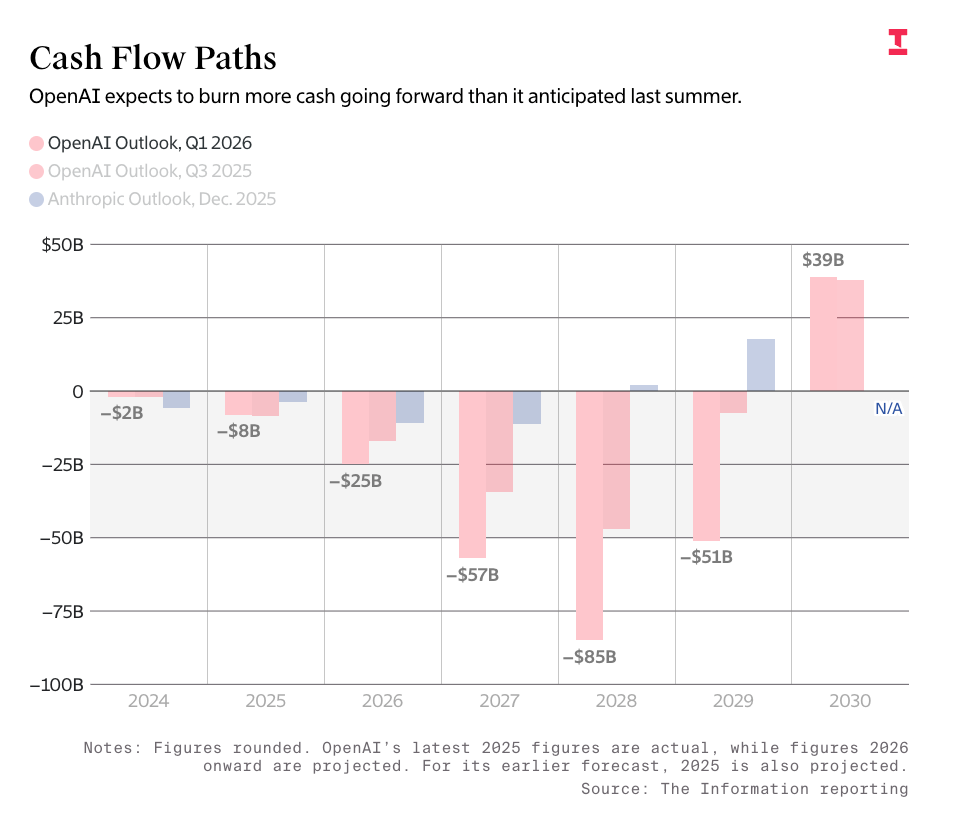
To be clear, OpenAI’s projections have it making $673 billion over the next four years, and burning $218 billion to get there. It is an incredibly unprofitable business, and even if it wasn’t, it would have to make so much more money than it currently does to pay Oracle on an ongoing basis.
I calculated that $75 billion number by assuming that Vera Rubin GPUs get around $14 million per megawatt of compute (a number I’ve confirmed with sources familiar with the data center industry) across the remaining 4.64GW of critical IT that I anticipate makes up the remaining Stargate data centers.
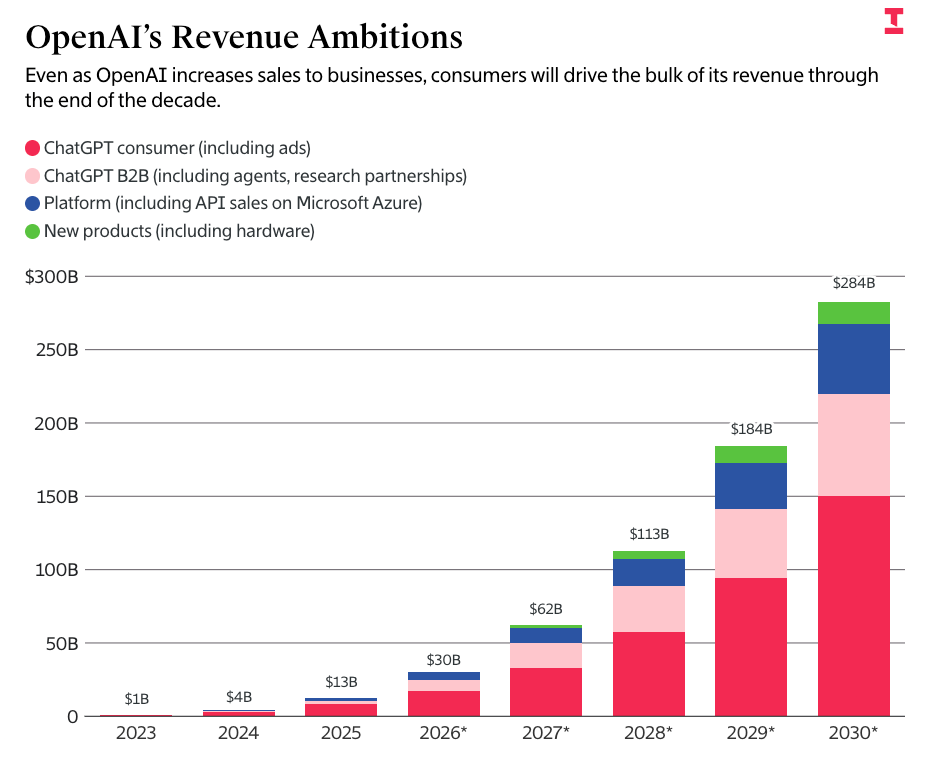
OpenAI’s numbers come directly from The Information’s reported leaks of OpenAI’s projected burn rate and revenues, which have the company making $673 billion in revenue through the end of 2030 and burning $852 billion to get there:
I must be clear that any journalist repeating these numbers without saying how fucking stupid they are should be a little ashamed of themselves. Per my Friday premium:
In other words, in two years OpenAI projects it will make more revenue than TSMC, in three years almost as much annual revenue as Meta, and by the end of 2030, as much annual revenue as Microsoft ($300 billion or so on a trailing 12 month basis).
And if OpenAI can’t pay for that compute, Oracle dies, because it’s taken on around $115 billion in debt just to build Stargate’s data centers, and needs another $150 billion to finish them:
Oracle is a company that currently makes around $64 billion in annual revenue, and had free cash flow of negative $24.7 billion in its last quarter. It raised $18 billion in bonds in September 2025, $25 billion in bonds in February 2026, it did a $20 billion at-the-market share sale sometime in March, and despite it being called “closed” for months, only appears to have recently closed its $38 billion in project financing for Stargate Wisconsin and Shackelford. I’m also including the $14 billion in data center debt related to Stargate Michigan.
Either way, Oracle is insufficiently-capitalized to finish Stargate Abilene. It will need at least another $150 billion to get this done, and that’s assuming that other partners pick up about $30 billion in costs. Honestly, it may be more.
I really need to be clear that Oracle has no other path to making this revenue without OpenAI, and these projects are entirely financed and paid for using the projected cashflow of the data centers themselves.
And I’m not even the only one worried about this, with OpenAI Sarah Friar sharing similar concerns after the company missed user and revenue targets, per the Wall Street Journal:
OpenAI recently missed its own targets for new users and revenue, stumbles that have raised concern among some company leaders about whether it will be able to support its massive spending on data centers.
Chief Financial Officer Sarah Friar has told other company leaders that she is worried the company might not be able to pay for future computing contracts if revenue doesn’t grow fast enough, according to people familiar with the matter.
Board directors have also more closely examined the company’s data-center deals in recent months and questioned Chief Executive Sam Altman’s efforts to secure even more computing power despite the business slowdown, the people said.
If that doesn’t worry you, perhaps this will:
She has emphasized to executives and board directors the need for OpenAI to improve its internal controls, cautioning that the company isn’t yet ready to meet the rigorous reporting standards required of a public company. Altman has favored a more aggressive timeline for an IPO, some of the people said.
That sure sounds like a company that’s gonna be able to make $852 billion by the end of the decade!
Anthropic Is Just As Bad As OpenAI, Committing To Up To 10GW ($100BN+ Annual Revenue) In Compute From Google and Amazon
While I regularly bag on OpenAI for its ridiculous promises, Anthropic isn’t far behind, promising to take “up to” 5GW of capacity from both Google and Amazon in a deal that I estimate includes around $100 billion in actual compute commitments given the scale of the capacity.
Now, I should add that Google and Amazon are far-savvier and less-desperate than Oracle, meaning that they can take the hit if Anthropic ends up running out of money. The “up to” part of that deal gives them some much-needed wiggle room that Oracle simply does not have.
Nevertheless, for Anthropic to actually meet its commitments, it will have to agree to spend anywhere from $25 billion to $100 billion a year on compute by the end of 2030.
Anthropic’s CFO said in March that it had made $5 billion in revenue in its entire existence.
There Needs To Be $156.8 Billion In AI Annual Compute Revenue To Support The 15.2GW of AI Data Centers Under Construction, and $1.18 Trillion To Support All 114GW Announced
The near-pornographic excitement around however many hundreds of billions of dollars of GPUs that Jensen Huang claims to be shifting regularly clouds out a problematic question: sell the compute to who, Jensen?
If we assume that the 15.2GW of data center capacity under construction (due by the end of 2028) has a PUE of around 1.35, that leaves us with roughly 11.2GW of critical IT. At $14 million per megawatt, that works out to around $156.8 billion in annual revenue in GPU rental revenue required to actually make these data centers worth it.
When you calculate for the 114GW of capacity theoretically coming online by the end of 2028, that number climbs to $1.18 trillion in annual revenue.
To give you some context, CoreWeave — the largest neocloud with Meta, OpenAI, Google (for OpenAI), Microsoft (for OpenAI), Anthropic, and NVIDIA as customers — made around $5.1 billion in revenue, and projected it would make $12 billion to $13 billion in 2026.
Who, exactly, is the customer for all this compute, and how likely is it that they’ll want to buy it by the time all that capacity is built? While many different data centers claim to have tenants for the first few years of their existence, said tenants can only start paying once the data center completes, and if it’s an AI startup, I think it’s fairly reasonable to ask whether they exist by the time it’s built.
Remember: the customers of AI compute are, for the most part, either hyperscalers trying to move capital expenditures off their balance sheets or unprofitable AI startups. Anthropic and OpenAI both intend to burn tens of billions of dollars in the next few years, and neither of them have a path to profitability.
This means that a large part — if not the majority of — AI compute revenue is dependent on a continual flow of venture capital and debt, both of which are only made possible by investors that still believe that generative AI will be the biggest, most hugest thing in the world.
How does that work out, exactly? Who is paying for this data center capacity? Who is it for? Where is the actual demand?
And if said demand exists, how the fuck do the customers even pay?
Generative AI Is Unprofitable and Unsustainable, And Only Getting More Expensive
Despite multiple stories that have both of them becoming profitable by 2028 or 2029, nobody can explain to me how OpenAI or Anthropic actually reach profitability, especially given that both of them had worse margins than expected, even when said margins strip out training costs that number in the billions of dollars.
And I’ve been asking this question for fucking years. Every time we get a new update on Anthropic or OpenAI, we hear they’ve lost billions more dollars than expected, that margins are decaying, that costs are skyrocketing, that everything is more expensive despite promises that the literal opposite would happen.
Even Cursor, a company that briefly (before its pseudo-acquisition by Musk’s SpaceX) claimed it had positive gross margins, actually had negative 23% gross margins as of January, or negative 31% if you include the cost of non-paying users, which you fucking should if you actually care about your accounting. Mysteriously, reports claim that Cursor’s margins “recently turned positive,” but magically don’t know by how much, or how that happened, or a single other detail other than one that likely helped the company get sold.
I also don’t see how any of these AI data centers actually make sense, even if they have customers to pay them for the first few years. The economics are built for perfection, with zero fault tolerance. They must have consistent, 100% utilization and tenancy, or they end up burning millions of dollars and fail to chip away at the years-long wall of depreciation created by the tech industry’s most expensive mistake.
Even if they somehow succeed, these are pathetic businesses with mediocre margins — 70% at best, assuming consistent payments, tenancy, and six fucking years of depreciation to actually break even, which might be difficult considering the yearly upgrade cycle makes the entire thing near-obsolete by the time you’re done paying it off.
And that’s before you consider that the majority of the customers are unprofitable, unsustainable startups.
I truly don’t know how any of this works out.
LLMs Are A Ripoff, And Customers Have Been Lied To
I realize it seems a little much, but I genuinely believe that subscription-based AI services were an act of deception tantamount to fraud, as they misrepresented the core unit economics and thus the possibilities of a Large Language Model. By selling users a product on a monthly rate and creating habits based on its availability, companies like Anthropic and OpenAI have misrepresented their businesses in such a way that most of their users are interacting with products and building workflows based on products that are unsustainable and impossible to maintain in their current form.
Anthropic’s recent aggressive rate limit changes were instituted mere months after multiple aggressive marketing campaigns based on experiences that are now near-impossible under the current rate limits, and based on recent moves by Anthropic, it’s clear that it intends to start removing services for its lower-tier $20-a-month subscribers at some time in the future. This is a disgusting and misleading way to run a company, and the vagueness with which Anthropic discusses its products and its services are an insult to every one of their users, and a sign that it doesn’t fear the press in any meaningful way.
I need to be very clear that the product that Anthropic offers — by virtue of recent rate limit changes — is substantially different (and far worse) than the one that you read about everywhere. Anthropic was conscious in its deliberate attempts to market a product that it knew would be gone within three months. Dario Amodei doesn’t give a fuck as long as the media keeps writing up however many billions of annualized revenue he’s conjured up today or whatever new product he’s released that’s meant to destroy some hapless public SaaS company that had already seen its growth slow.
Members of the media, I say this with abundant respect: Anthropic is mistreating its customers, and it is doing so because it believes it can get away with it. This company does not respect you, and in fact holds you with a remarkable degree of contempt, which is why it doesn’t bother to fix its services very quickly or explain why they were broken with any level of coherence.
That’s why Anthropic fucking lied about Claude Mythos being too powerful to release (it was actually a capacity issue) when in fact it’s just another fucking Large Language Model Nothingburger — because it thinks you will buy whatever it is selling, and it’s worked out exactly how to package it to give you enough plausible “proof” that a quick skimread of the system card will make you and your editor believe whatever it is you’re saying.
They also know you’ll rush to cover it rather than waiting to see what actual experts say.
AI is a con, and this is how the con works. AI was rushed and pushed in our faces as quickly as humanly possible in the least-efficient yet most-accessible form it could be presented, even if said form was never going to result in anything resembling a sustainable business. The media was rushed to immediately say that this was the thing so that everybody would agree that this was the thing now and use it as much as physically possible, and, crucially, use it in a subscription-based form that would make people experience it without ever asking how much it costs to provide.
The narrative came pre-baked. Because very few people who talked about LLMs experienced their actual cost, it was really easy for them to vaguely say “it’s just like Uber,” because that was a company that lost a lot of money but didn’t die, and it’s much easier to say that than say “wait, what do you mean OpenAI is set to lose $5 billion this year?”
Think of it like this: as a reporter, an investor, an executive, or a regular LinkedIn Lounge Lizard, you might read here and there that it’s $5 per million input tokens and $25 per million output tokens, but you’ve never really experienced how fast or slow one loses that money, because it’s important to do so to truly understand this product. Anthropic and OpenAI intentionally obfuscated that experience and created businesses that expect to burn tens of billions of dollars in 2026 and several hundred billion dollars by 2030, all because most people graded generative AI based on the subscription-based experience.
LLMs are a casino, and you’ve been gambling with the house’s money while encouraging people to bet their own on whether they’ll get a unit of work out of a particular model.
This was intentional. They never wanted you thinking about the costs because once you really start thinking about the costs this whole thing feels a little insane. I truly believe that LLM-based subscriptions are going to go away entirely, at least at the scale of any product that generates code, and in doing so, Amodei and Altman will wrap up their con, or at least believe that they have.
The problem is that these men have now signed far too many deals to get away scot-free.
OpenAI’s CFO has now said multiple times that she doesn’t believe OpenAI is ready for IPO, and has material concerns about its growth and continued ability to meet its obligations. To repeat a quote from before:
Chief Financial Officer Sarah Friar has told other company leaders that she is worried the company might not be able to pay for future computing contracts if revenue doesn’t grow fast enough, according to people familiar with the matter.
This is a blinking red fucking light, and in a sane market would send Oracle’s stock into a tailspin, because OpenAI’s ascent to over $280 billion in annual revenue is critical to Oracle’s ability to not run out of money. In a sane media, this would send worrisome shockwaves through every group chat and Slack channel about whether or not OpenAI is actually going to make it.
This is the kind of thing that happens before a company starts dying. OpenAI’s growth is slowing at precisely the time it needs to accelerate. It needs to effectively 10x its current business by 2030 to make its obligations. OpenAI’s CFO, the literal person who would know best, is saying that she is worried that OpenAI cannot pay its fucking compute contracts if revenue doesn’t grow. This is a big, blinking warning light! This is not a drill!
Yet the bit that really worried me was the Journal’s comment that Friar didn’t think OpenAI “was ready to meet the rigorous reporting standards required of a public company.”
What the fuck does that mean? Excuse me? This company has allegedly raised $122 billion and is allegedly worth $852 billion god damn dollars and expects to burn $852 billion dollars by the end of 2030. Are its accounts not in order? What “rigorous reporting standards” can OpenAI not meet?
I’d generally not be so fucking nosy if it wasn’t for the fact that this company accounted for something like 20% of all venture capital funding in the last year and everywhere I go I have to hear the endless bloviating of Altman and Brockman and every other man at OpenAI and their fucking ideas about what regular people should do as they swan about shipping dogshit software and spending other people’s money.
For the amount of oxygen that both Anthropic and OpenAI consume, both of these companies should be fucking flawless, both as products and businesses. Instead, both are sold through varying levels of deception around their economics and efficacy, obfuscating the truth so that their Chief Executives can amass money and power and attention. It’s an insult to both good software and good taste — the most-expensive, least-reliable applications ever invented, their mistakes forgiven, their mediocrities celebrated, their infrastructure hailed as an inert god of capital.
Generative AI is an insult. It is unreliable, its economics don’t make sense, its outcomes don’t justify its existence, and the perpetrators of its con are boring, oafish and avaricious men disconnected from society and anybody who would ever disagree with them. It requires stealing art from everybody, destroying the environment, increasing our electricity bills, the constant threat of economic annihilation, the endless cacaphony of “everything fucking sucks now because of AI,” all to push software that can only be justified by people willing to ignore basic finance or sense.
It’s all so expensive, and it’s all so fucking dull. It’s offensively boring. It’s actively annoying. Every story where somebody tells you about how much they use AI sounds like they’re in an abusive relationship and/or joined a cult, echoing with a subtle desperation that says “you really need to join me in this because it’s so good, and the fact that I appear to be experiencing no joy from this product is just a sign of how efficient it is.” There is nothing light-hearted or joyful about what AI can do. There is nothing goofy or whimsical about a Large Language Model, and every interaction feels hollow.
Those who desperately look for clues that it’s becoming sentient or “more powerful” are simply seeking validation themselves — they want to be first to something, because arriving at other people’s conclusion is what they do for a living.
Being “first” — on the “frontier” one might say — is something that people crave when they can’t find something within, and it’s exactly the fuel that grifters crave, because LLMs are constantly humming with the sense that they’re about to do something new, even though they’re mathematically restricted to repeating other actions.
This is a deeply sad era. The people that have so aggressively worked together to hold up this industry have only delayed its inevitable fall. It’s terrifying to me that our markets and parts of our economy are being held up by the generally-held yet utterly-unproven assumption that LLMs will somehow get cheaper, that AI startups will magically become profitable, and that offering AI compute will be profitable in perpetuity to the point that it necessitates increasing the current supply tenfold by the year 2030.
People have debased themselves to defend the AI industry, because that’s what the industry demands of its supplicants. To be an “AI expert” requires you to actively ignore the worst economics of any industry in history, to constantly explain away obvious, glaring issues with products, and to actively convince others to do the same. OpenAI and Anthropic do not provide clear explanations of how they’ll become profitable because they know that their supporters will never ask for them — because the only way to fully “believe in AI” is to actively wear blinders.
And I get it. If you accept that OpenAI and/or Anthropic will eventually collapse, all of this seems a little insane. I am genuinely asking you to seriously consider that one or both of these companies will run out of money.
I’m really worried, made only more so by the general lack of concern I’m seeing in the media and greater society.
The assumption, if I had to imagine, is that I’m simply being alarmist, and that “the demand will absolutely be there.”
You’d better hope you’re right.
For Larry Ellison’s sake, at least. Ellison has already pledged 346 million shares of his Oracle stock — or around $61.5 billion — “to secure certain personal indebtedness, including various lines of credit,” meaning “many big, beautiful loans against his Oracle shares.” which IFR estimated back in September (when Oracle’s stock price was much higher) could allow him to secure as much as $21.4 billion in debt at a (they say “conservative”) loan-to-value ratio of 20%, and that’s assuming the banks weren’t particularly generous.
If OpenAI can’t raise $852 billion in revenue and funding by the end of 2030, it won’t be able to pay for Stargate. That’ll kill the value of Oracle’s stock, leading to a series of margin calls, leading to Ellison having to sell shares, leading to further margin calls. Whatever bailout might or might not exist won’t save Larry’s estate.
What I’m saying is that Ellison’s future rides on Sam Altman’s ability to raise funding and make revenue to the tune of $852 billion in the space of 4 years.
Good luck, Larry! You’re going to need it.
