
Hi! If you like this piece and want to support my independent reporting and analysis, why not subscribe to my premium newsletter? It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5000 to 18,000 words, including vast, detailed analyses of NVIDIA, Anthropic and OpenAI’s finances, and the AI bubble writ large. I just put out a massive Hater’s Guide To The SaaSpocalypse, as well as the Hater’s Guide to Adobe. It helps support free newsletters like these!
The entire AI bubble is built on a vague sense of inevitability — that if everybody just believes hard enough that none of this can ever, ever go wrong that at some point all of the very obvious problems will just go away.
Sadly, one cannot beat physics.
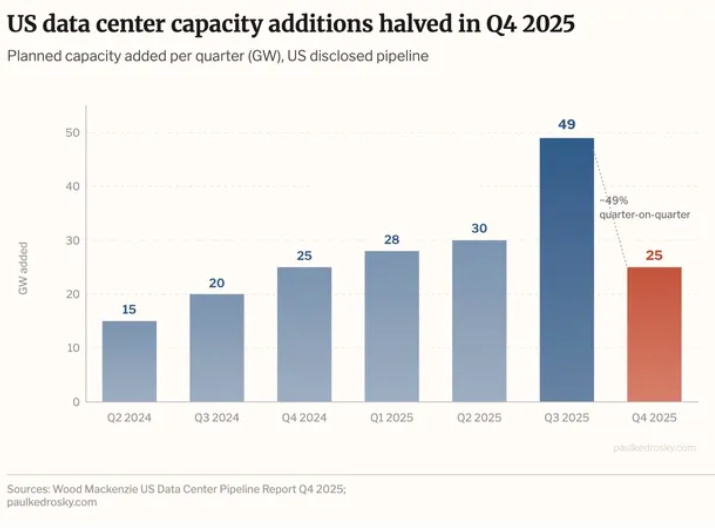
Last week, economist Paul Kedrosky put out an excellent piece centered around a chart that showed new data center capacity additions (as in additions to the pipeline, not brought online) halved in the fourth quarter of 2025 (per data from Wood Mackenzie):
Wood Mackenzie’s report framed it in harsh terms:
US data-centre capacity additions halved from Q3 to Q4 2025 as load-queue challenges persisted. The decline underscores the difficulties of the current development environment and signals a resulting focus on existing pipeline projects. While Texas extended its pipeline capacity lead in Q4 2025, New Mexico, Indiana and Wyoming saw greater relative growth. Planned capacity continues to be weighted by new developers with a small number of massive, speculative projects, targeting in particular the South and Southwest. New Mexico owes its growth to a single, massive, speculative project by New Era Energy & Digital in Lea County.
As I said above, this refers only to capacity that’s been announced rather than stuff that’s actually been brought online, and Kedrosky missed arguably the craziest chart — that of the 241GW of disclosed data center capacity, only 33% of it is actually under active development:
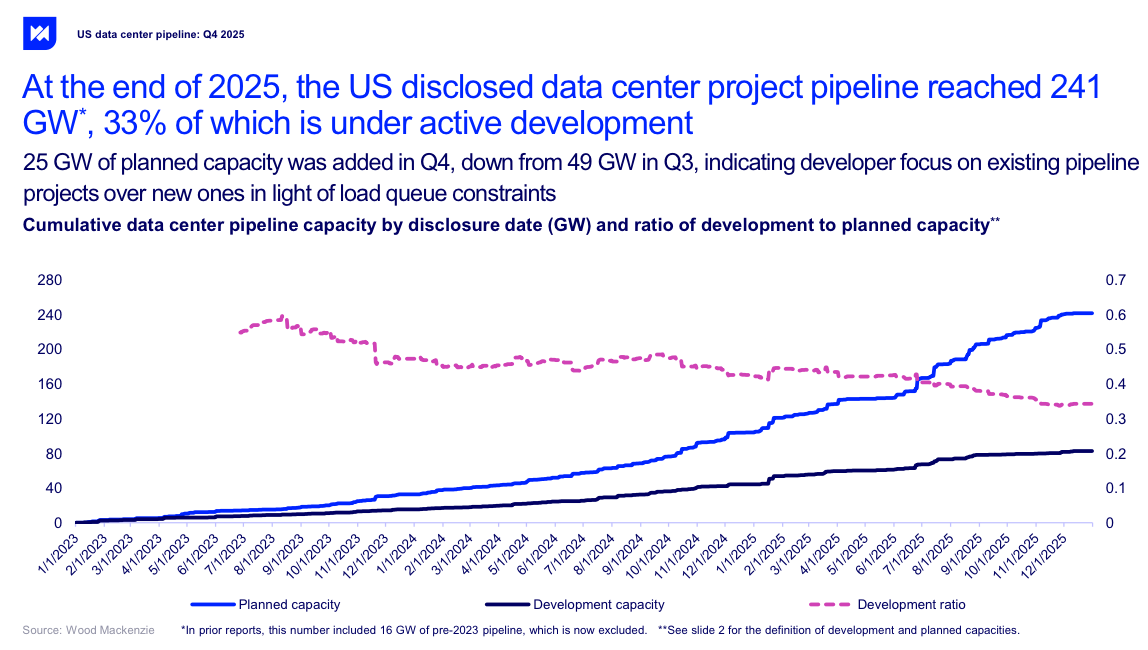
The report also adds that the majority of committed power (58%) is for “wires-only utilities,” which means the utility provider is only responsible for getting power to the facility, not generating the power itself, which is a big problem when you’re building entire campuses made up of power-hungry AI servers.
WoodMac also adds that PJM, one of the largest utility providers in America, “...remains in trouble, with utility large load commitments three times as large as the accredited capacity in PJM’s risked generation queue,” which is a complex way of saying “it doesn’t have enough power.”
This means that fifty eight god damn percent of data centers need to work out their own power somehow. WoodMac also adds there is around $948 billion in capex being spent in totality on US-based data centers, but capex growth decelerated for the first time since 2023. Kedrosky adds:
The total announced pipeline looks huge at 241 GW — about twice US peak electricity demand — but most of it is not real. Only a third is under construction, with the rest a mix of hopeful permits, speculative land deals, and projects that assume power sources nobody has actually built yet. In particular, much of it assumes on-site gas plants, a fraught assumption given current geopolitics.
The most serious problem is in the mid-Atlantic. Regional grid operator PJM has made power commitments to data centers at roughly three times the rate that new generation is actually coming online. Someone is going to be waiting a very long time, or paying a lot more than they expected, or both.
Let’s simplify:
- Only 33% of announced US data centers are actually being built, with the rest in vague levels of “planning.” That’s about 79.53GW of power, or 61GW of IT load.
- “Active development” also refers to anything that is (and I quote) “...under development or construction,” meaning “we’ve got the land and we’re still working out what to do with it.
- This is pretty obvious when you do the maths. 61GW of IT load would be hundreds of thousands of NVIDIA GB200 NVL72 racks — over a trillion dollars of GPUs at $3 million per 72-GPU rack — and based on the fact there were only $178.5 billion in data center debt deals last year, I don’t think many of these are actually being built right now.
- Even if they were, there’s not enough power for them to turn on.
- NVIDIA claims it will sell $1 trillion of GPUs between 2025 and 2027, and as I calculated previously, it sells about 1.6GW (in IT load terms, as in how much power just the GPUs draw) of GPUs every quarter, which would require at least 1.95GW of power just to run, when you include all the associated gear and the challenges of physically getting power.
- None of this data talks about data centers actually coming online.
How Much Actual Data Center Capacity Came Online In 2025? My Estimate: 3GW of IT Load
The term you’re looking for there is data center absorption, which is (to quote Data Center Dynamics) “...the net growth in occupied, revenue-producing IT load,” which grew in America’s primary markets from 1.8GW in new capacity in 2024 to 2.5GW of new capacity in 2025 according to CBRE.
Definition sidenote! “Colocation” space refers to data center space built that is then rented out to somebody else, versus data centers explicitly built for a company (such as Microsoft’s Fairwater data centers). What’s interesting is that it appears that some — such as Avison Young — count Crusoe’s developments (such as Stargate Abilene) as colocation construction, which makes the collocation numbers I’ll get to shortly much more indicative of the greater picture.
The problem is, this number doesn’t actually express newly-turned-on data centers. Somebody expanding a project to take on another 50MW still counts as “new absorption.”
Things get more confusing when you add in other reports. Avison Young’s reports about data center absorption found 700MW of new capacity in Q1 2025, 1.173GW in Q2, a little over 1.5GW in Q3 and 2.033GW in Q4 (I cannot find its Q3 report anywhere), for a total of 5.44GW, entirely in “colocation,” meaning buildings built to be leased to others.
Yet there’s another problem with that methodology: these are facilities that have been “delivered” or have a “committed tenant.” “Delivered” could mean “the facility has been turned over to the client, but it’s literally a powered shell (a warehouse) waiting for installation,” or it could mean “the client is up and running.” A “committed tenant” could mean anything from “we’ve signed a contract and we’re raising funds” (such as is the case with Nebius raising money off of a Meta contract to build data centers at some point in the future).
We can get a little closer by using the definitions from DataCenterHawk (from whichAvison Young gets its data), which defines absorption as follows:
To measure demand, we want to know how much capacity was leased up by customers over a specific period of time. At datacenterHawk we calculate this quarterly. The resulting number is what’s called absorption.
Let’s say DC#1 has 10 MW commissioned. 9 MW are currently leased and 1 MW is available. Over the course of a quarter, DC#1 leases up that last MW to a few tenants. Their absorption for the quarter would be 1 MW. It can get a little more complicated but that’s the basic concept.
That’s great! Except Avison Young has chosen to define absorption in an entirely different way — that a data center (in whatever state of construction it’s in) has been leased, or “delivered,” which means “a fully ready-to-go data center” or “an empty warehouse with power in it.”
CBRE, on the other hand, defines absorption as “net growth in occupied, revenue-producing IT load,” and is inclusive of hyperscaler data centers. Its report also includes smaller markets like Charlotte, Seattle and Minneapolis, adding a further 216MW in absorption of actual new, existing, revenue-generating capacity.
So that’s about 2.716GW of actual, new data centers brought online. It doesn’t include areas like Southern Virginia or Columbus, Ohio — two massive hotspots from Avison Young’s report — and I cannot find a single bit of actual evidence of significant revenue-generating, turned-on, real data center capacity being stood up at scale. DataCenterMap shows 134 data centers in Columbus, but as of August 2025, the Columbus area had around 506MW in total according to the Columbus Dispatch, though Cushman and Wakefield claimed in February 2026 that it had 1.8GW.
Things get even more confusing when you read that Cushman and Wakefield estimates that around 4GW of new colocation supply was “delivered” in 2025, a term it does not define in its actual report, and for whatever reason lacks absorption numbers. Its H1 2025 report, however, includes absorption numbers that add up to around 1.95GW of capacity…without defining absorption, leaving us in exactly the same problem we have with Avison Young.
Nevertheless, based on these data points, I’m comfortable estimating that North American data center absorption — as the IT load of data centers actually turned on and in operation — was at around 3GW for 2025, which would work out to about 3.9GW of total power.
And that number is a fucking disaster.
It Is Currently Taking 6 Months To Install A Quarter of NVIDIA’s GPU Sales, Calling Into Question The Logic of Buying More GPUs
Earlier in the year, TD Cowen’s Jerome Darling told me that GPUs and their associated hardware cost about $30 million a megawatt. 3GW of IT load (as in the GPUs and their associated gear’s power draw) works out to around $90 billion of NVIDIA GPUs and the associated hardware, which would be covered under NVIDIA’s “data center” revenue segment:
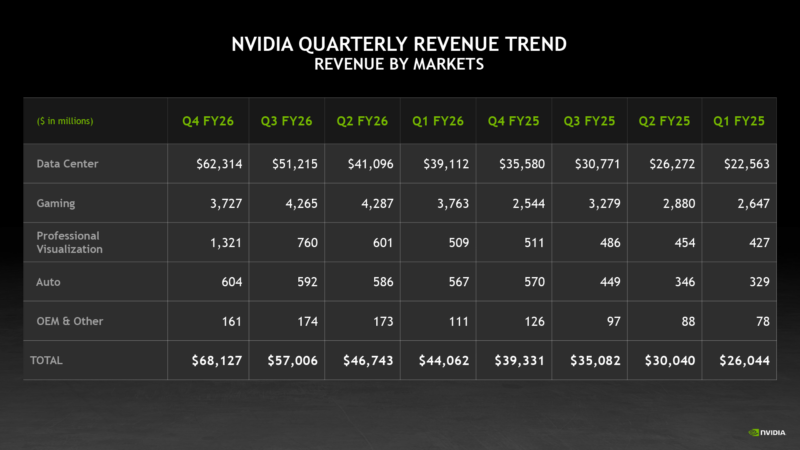
America makes up about 69.2% of NVIDIA’s revenue, or around $149.6 billion in FY2026 (which runs, annoyingly, from February 2025 to January 2026). NVIDIA’s overall data center segment revenue was $195.7 billion, which puts America’s data center purchases at around $135 billion, leaving around $44 billion of GPUs and associated technology uninstalled.
With the acceleration of NVIDIA’s GPU sales, it now takes about 6 months to install and operationalize a single quarter’s worth of sales. Because these are Blackwell (and I imagine some of the new next generation Vera Rubin) GPUs, they are more than likely going to new builds thanks to their greater power and cooling requirements, and while some could in theory be going to old builds retrofitted to fit them, NVIDIA’s increasingly-centralized (as in focused on a few very large customers) revenue heavily suggests the presence of large resellers like Dell or Supermicro (which I’ll get to in a bit) or the Taiwanese ODMs like Foxconn and Quanta who manufacture massive amounts of servers for hyperscaler buildouts.
I should also add that it’s commonplace for hyperscalers to buy the GPUs for their colocation partners to install, which is why Nebius and Nscale and other partners never raise more than a few billion dollars to cover construction costs.
It’s becoming very obvious that data center construction is dramatically slower than NVIDIA’s GPU sales, which continue to accelerate dramatically every single quarter.
Even if you think AI is the biggest most hugest and most special boy: what’s the fucking point of buying these things two to four years in advance? Jensen Huang is announcing a new GPU every year!
By the time they actually get all the Blackwells in Vera Rubin will be two years old! And by the time we install those Vera Rubins, some other new GPU will be beating it!
There Is Only 5GW of Global Data Center Capacity Actually Under Construction, And Every Huge, Multi-Gigawatt Project You Read Is Going To Take 2 to 4 Years Or More To Complete — And Wood Mackenzie Believes Capex Growth Will Slow In 2026
Before we go any further, I want to be clear how difficult it is to answer the question “how long does a data center take to build?”. You can’t really say “[time] per megawatt” because things become ever-more complicated with every 100MW or so. As I’ll get into, it’s taken Stargate Abilene two years to hit 200MW of power.
Not IT load. Power.
Anyway, the question of “how much data center capacity came online?” is pretty annoying too.
Sightline’s research — which estimated that “almost 6GW of [global data center power] capacity came online last year” — found that while 16GW of capacity was slated to come online in 2026 across 140 projects, only 5GW is currently under construction, and somehow doesn’t say that “maybe everybody is lying about timelines.”
Sightline believes that half of 2026’s supposed data center pipeline may never materialize, with 11GW of capacity in the “announced” stage with “...no visible construction progress despite typical build timelines of 12-18 months.” “Under construction” also can mean anything from “a single steel beam” to “nearly finished.”
These numbers also are based on 5GW of capacity, meaning about 3.84GW of IT load, or about $111.5 billion in GPUs and associated gear, or roughly 57.5% of NVIDIA’s FY2026 revenue that’s actually getting built.
Sightline (and basically everyone else) argues that there’s a power bottleneck holding back data center development, and Camus explains that the biggest problem is a lack of transmission capacity (the amount of power that can be moved) and power generation (creating the power itself):
The biggest driver of delay is simple: our power system doesn’t have enough extra transmission capacity and generation to serve dozens of gigawatts of new, high-utilization demand 100% of the time. Data centers require round-the-clock power at levels that rival or exceed the needs of small cities, and building new transmission infrastructure and generation requires years of permitting, land acquisition, supply chain management, and construction.
Camus adds that America also isn’t really prepared to add this much power at once:
Inside utilities, planners and engineers are working diligently to connect new loads. But the tools available to planners were built for extending power lines to new neighborhoods or upgrading equipment as communities grow. They weren’t designed to analyze 50 new service requests of 100 MW each, all while new generation applications pile up.
As a result, planners and engineers are overwhelmed; they’re stuck working to review new applications while simultaneously configuring new tools that are better equipped for the scale of this challenge. And unlike generation interconnection, which has well-defined steps across most ISOs and utilities, the process for evaluating large loads is often much more ad hoc. This makes adopting the right tools much more difficult too. In fact, the majority of utilities and ISO/RTOs are still developing formal study procedures.
Nevertheless, I also think there’s another more-obvious reason: it takes way longer to build a data center than anybody is letting on, as evidenced by the fact that we only added 3GW or so of actual capacity in America in 2025. NVIDIA is selling GPUs years into the future, and its ability to grow, or even just maintain its current revenues, depends wholly on its ability to convince people that this is somehow rational.
Let me give you an example. OpenAI and Oracle’s Stargate Abilene data center project was first announced in July 2024 as a 200MW data center. In October 2024, the joint venture between Crusoe, Blue Owl and Primary Digital Infrastructure raised $3.4 billion, with the 200MW of capacity due to be delivered “in 2025.” A mid-2025 presentation from land developer Lancium said it would have “1.2GW online by YE2025.” In a May 2025 announcement, Crusoe, Blue Owl, and Primary Digital Infrastructure announced the creation of a $15 billion joint vehicle, and said that Abilene would now be 8 buildings, with the first two buildings being energized by the “first half of 2025,” and that the rest would be “energized by mid-2026.” Each building would have 50,000 GPUs, and the total IT load is meant to be 880MW or so, with a total power draw of 1.2GW.
I’m not interested in discussing OpenAI not taking the supposedly-planned extensions to Abilene because it never existed and was never going to happen.
In December 2025, Oracle stated that it had “delivered” 96,000 GPUs, and in February, Oracle was still only referring to two buildings, likely because that’s all that’s been finished. My sources in Abilene tell me that Building Three is nearly done, but…this thing is meant to be turned on in mid-2026. Developer Mortensen claims the entire project will be completed by October 2026, which it obviously, blatantly won’t.
The AI Industry Is Trying To Hide The Incredibly Slow Growth of Data Centers, And Is Using The Media To Do So
I hate to speak in conspiratorial terms, but this feels like a blatant coverup with the active participation of the press. CNBC reported in September 2025 that “the first data center in $500 billion Stargate project is open in Texas,” referring to a data center with an eighth of its IT load operational as “online” and “up and running,” with Crusoe adding two weeks later that it was “live,” “up and running” and “continuing to progress rapidly,” all so that readers and viewers would think “wow, Stargate Abilene is up and running” despite it being months if not years behind schedule.
At its current rate of construction, Stargate Abilene will be fully built sometime in late 2027. Oracle’s Port Washington Data Center, as of March 6 2026, consisted of a single steel beam. Stargate Shackelford Texas broke ground on December 15 2025, and as of December 2025, construction barely appears to have begun in Stargate New Mexico. Meta’s 1GW data center campus in Indiana only started construction in February 2026.
And, despite Microsoft trying to mislead everybody that its Wisconsin data center had ‘arrived” and “been built,” looking even an inch deeper suggests very little has actually come online” — and, considering the first data center was $3.3 billion (remember: $14 million a megawatt just for construction), I imagine Microsoft has successfully brought online about 235MW of power for Fairwater.
What Microsoft wants you to think is it brought online gigawatts of power (always referred to in the future tense), because Microsoft, like everybody else, is building data centers at a glacial pace, because construction takes forever, even if you have the power, which nobody does!
The concept of a hundred-megawatt data center is barely a few years old, and I cannot actually find a built, in-service gigawatt data center of any kind, just vague promises about theoretical Stargate campuses built for OpenAI, a company that cannot afford to pay its bills.
Everybody keeps yammering on about “what if data centers don’t have power” when they should be thinking about whether data centers are actually getting built. Microsoft proudly boasted in September 2025 about its intent to build “the UK’s largest supercomputer” in Loughton, England with Nscale, and as of March 2026, it’s literally a scaffolding yard full of pylons and scrap metal. Stargate Abilene has been stuck at two buildings for upwards of six months.
Here’s what’s actually happening: data center deals are being funded by eager private credit gargoyles that don’t know shit about fuck. These deals are announced, usually by overly-eager reporters that don’t bother to check whether the previous data centers ever got built, as massive “multi-gigawatt deals,” and then nobody follows up to check whether anything actually happened.
All that anybody needs to fund one of these projects is an eager-enough financier and a connection to NVIDIA. All Nebius had to do to raise $3.75 billion in debt was to sign a deal with Meta for data center capacity that doesn’t exist and will likely take three to four years to build (it’s never happening). Nebius has yet to finish its Vineland, New Jersey data center for Microsoft, which was meant to be “at 100MW” by the end of 2025, but appears to have only had 50MW (the first phase) available as of February 2026.
I’m just gonna come out and say it: I think a lot of these data center deals are trash, will never get built, and thus will never get paid. The tech industry has taken advantage of an understandable lack of knowledge about construction or power timelines in the media to pump out endless stories about “data center capacity in progress” as a means of obfuscating an ever-growing scandal: that hundreds of billions of NVIDIA GPUs got sold to go in projects that may never be built.
These things aren’t getting built, or if they’re getting built, it’s taking way, way longer than expected, which means that interest on that debt is piling up. The longer it takes, the less rational it becomes to buy further NVIDIA GPUs — after all, if data centers are taking anywhere from 18 months to three years to build, why would you be buying more of them? Where are you going to put them, Jensen?
This also seriously brings into question the appetite that private credit and other financiers have for funding these projects, because much of the economic potential comes from the idea that these projects get built and have stable tenants. Furthermore, if the supply of AI compute is a bottleneck, this suggests that when (or if) that bottleneck is ever cleared, there will suddenly be a massive supply glut, lowering the overall value of the data centers in progress…which are, by the way, all filled with Blackwell GPUs, which will be two or three-years-old by the time the data centers are finally turned on.
That’s before you get to the fact that the ruinous debt behind AI data centers makes them all remarkably unprofitable, or that their customers are AI startups that lose hundreds of millions or billions of dollars a year, or that NVIDIA is the largest company on the stock market, and said valuation is a result of a data center construction boom that appears to be decelerating and even if it wasn’t operating at a glacial pace compared to NVIDIA’s sales.
Not to sound unprofessional or nothing, but what the fuck is going on? We have 241GW of “planned” capacity in America, of which only 79.5GW of which is “under active development,” but when you dig deeper, only 5GW of capacity is actually under construction?
The entire AI bubble is a god damn mirage. Every single “multi-gigawatt” data center you hear about is a pipedream, little more than a few contracts and some guys with their hands on their hips saying “brother we’re gonna be so fuckin’ rich!” as they siphon money from private credit — and, by extension, you, because where does private credit get its capital from? That’s right. A lot comes from pension funds and insurance companies.
Here’s the reality: data centers take forever. Every hyperscaler and neocloud talking about “contracted compute” or “planned capacity” may as well be telling you about their planned dinners with The Grinch and Godot. The insanity of the AI buildout will be seen as one of the largest wastes of capital of all time (to paraphrase JustDario), and I anticipate that the majority of the data center deals you’re reading about simply never get built.
The fact that there’s so much data about data center construction and so little data about completed construction suggests that those preparing the reports are in on the con. I give credit to CBRE, Sightline and Wood Mackenzie for having the courage to even lightly push back on the narrative, even if they do so by obfuscating terms like “capacity” or “power” in ways that reporters and other analysts are sure to misinterpret.
Hundreds of billions of dollars have been sunk into buying GPUs, in some cases years in advance, to put into data centers that are being built at a rate that means that NVIDIA’s 2025 and 2026 revenues will take until 2028 to 2029 to actually operationalize, and that’s making the big assumption that any of it actually gets built.
I think it’s also fair to ask where the money is actually going. 2025’s $178.5 billion in US-based data center deals doesn’t appear to be resulting in any immediate (or even future) benefit to anybody involved.
I also wonder whether the demand actually exists to make any of this worthwhile, or what people are actually paying for this compute.
If we assume 3GW of IT load capacity was brought online in America, that should (theoretically) mean tens of billions of dollars of revenue thanks to the “insatiable demand for AI” — except nobody appears to be showing massive amounts of revenue from these data centers.
Applied Digital only had $144 million in revenue in FY2025 (and lost $231 million making it). CoreWeave, which claimed to have “850MW of active power (or around 653MW of IT load)” at the end of 2025 (up from 420MW in Q1 FY2025, or 323MW of IT load), made $5.13 billion of revenue (and lost $1.2 billion before tax) in FY2025.
Nebius? $228 million, for a loss of $122.9 million on 170MW of active power (or around 130MW of IT load). Iren lost $155.4 million on $184.7 million last quarter, and that’s with a release of deferred tax liabilities of $182.5 million. Equinix made about $9.2 billion in revenue in its last fiscal year, and while it made a profit, it’s unclear how much of that came from its large and already-existent data center portfolio, though it’s likely a lot considering Equinix is boasting about its “multi-megawatt” data center plans with no discussion of its actual capacity.
And, of course, Google, Amazon, and Microsoft refuse to break out their AI revenues. Based on my reporting from last year, OpenAI spent about $8.67 billion on Azure through September 2025, and Anthropic around $2.66 billion in the same period on Amazon Web Services. As the two largest consumers of AI compute, this heavily suggests that the actual demand for AI services is pretty weak, and mostly taken up by a few companies (or hyperscalers running their own services.)
At some point reality will set in and spending on NVIDIA GPUs will have to decline. It’s truly insane how much has been invested so many years in the future, and it’s remarkable that nobody else seems this concerned.
Simple questions like “where are the GPUs going?” and “how many actual GPUs have been installed?” are left unanswered as article after article gets written about massive, multi-billion dollar compute deals for data centers that won’t be built before, at this rate, 2030.
And I’d argue it’s convenient to blame this solely on power issues, when the reality is clearly based on construction timelines that never made any sense to begin with. If it was just a power issue, more data centers would be near or at the finish line, waiting for power to be turned on. Instead, well-known projects like Stargate Abilene are built at a glacial pace as eager reporters claim that a quarter of the buildings being functional nearly a year after they were meant to be turned on is some sort of achievement.
Then there’s the very, very obvious scandal that NVIDIA, the largest company on the stock market, is making hundreds of billions of dollars of revenue on chips that aren’t being installed. It’s fucking strange, and I simply do not understand how it keeps beating and raising expectations every quarter given the fact that the majority of its customers are likely going to be able to use their current purchases in the next decade.
Assuming that Vera Rubin actually ships in 2026, it’s reasonable to believe that people will be installing these things well into 2028, if not further, and that’s assuming everything doesn’t collapse by then. Why would you bother? What’s the point, especially if you’re sitting on a pile of Blackwell GPUs?
Why are we doing any of this?
Jensen, How Do All These NVIDIA GPUs Keep Getting To China?
Last week also featured a truly bonkers story about Supermicro, a reseller of GPUs used by CoreWeave and Crusoe, where co-founder Wally Liaw and several other co-conspirators were arrested for selling hundreds of millions of dollars of NVIDIA GPUs to China, with the intent to sell billions more.
Liaw, one of Supermicro’s co-founders, previously resigned in a 2018 accounting scandal where Supermicro couldn’t file its annual reports, only to be (per Hindenburg Research’s excellent report) rehired in 2021 as a consultant, and restored to the board in 2023, per a filed 8K.
Mere days before his arrest, Liaw was parading around NVIDIA’s GTC conference, pouring unnamed liquids in ice luges and standing two people away from NVIDIA CEO Jensen Huang. Liaw was also seen congratulating the CEO of Lambda on its new CFO appointment on LinkedIn, as well as shaking hands (along with Supermicro CEO Charles Liang, who has not been arrested or indicted) with Crusoe (the company building OpenAI’s Abilene data center) CEO Chase Lochmiller.
Supermicro isn’t named in the indictment for reasons I imagine are perfectly normal and not related to keeping the AI party going. Nevertheless, Liaw and his co-conspirators are accused of shipping hundreds of millions of dollars’ worth of NVIDIA GPUs to China through a web of counterparties and brokers, with over $510 million of them shipped between April and mid-May 2025. While the indictment isn’t specific as to the breakdown, it confirms that some Blackwell GPUs made it to China, and I’d wager quite a few.
The mainstream media has already stopped thinking about this story, despite Supermicro being a huge reseller of NVIDIA gear, contributing billions of dollars of revenue, with at least $500 million of that apparently going to China. The fact that Supermicro wasn’t specifically named in the case is enough to erase the entire tale from their minds, along with any wonder about how NVIDIA, and specifically Jensen Huang, didn’t know.
This also isn’t even close to the only time this has happened. Late last year, Bloomberg reported on Singapore-based Megaspeed — a (to quote Bloomberg) “once-obscure spinoff of a Chinese gaming enterprise [that] evolved into the single largest Southeast Asian buyer of NVIDIA chips” — and highlighted odd signs that suggest it might be operating as a front for China.
As a neocloud, Megaspeed rents out AI compute capacity like CoreWeave, and while NVIDIA (and Megaspeed) both deny any of their GPUs are going to China, Megaspeed, to quote Bloomberg, has “something of a Chinese corporate twin”:
This firm used similar presentation materials to Megaspeed’s, had a nearly identical website to a Megaspeed sub-brand and claimed Megaspeed’s Southeast Asia employees as its own. It’s also posted job ads at and near the Shanghai data center whose rendering was used in Megaspeed’s investor deck — including for engineering work on restricted Nvidia GPUs.
Bloomberg reported that Megaspeed imported goods “worth more than a thousand times its cash balance in 2023,” with two-thirds of its imports being NVIDIA products. The investigation got weirder when Bloomberg tried to track down specific circuit boards that NVIDIA had told the US government were in specific sites:
Data centers aren’t the only Megaspeed facilities Nvidia visited. The vast majority of Megaspeed’s $2.4 billion worth of Bianca boards, the circuit boards that house Nvidia’s top-end GB200 and GB300 semiconductors, were unaccounted for at the sites Nvidia described to Washington. After Bloomberg asked about those products, the chipmaker went to separate Megaspeed warehouses, an Nvidia official said, and confirmed the Bianca boards are there.
This person declined to specify the number observed in storage, nor where and when the chips — imported more than half a year ago — would be put to use. “Building data centers is a complex process that takes many months and involves many suppliers, contractors and approvals,” an Nvidia spokesperson said.
Things get weirder throughout the article, with a Chinese company called “Shanghai Shuoyao” having a near-identical website and investor deck (as mentioned) to Megaspeed, with several of the “computing clusters under construction” actually being in China.

Things get a lot weirder as Bloomberg digs in, including a woman called “Huang” that may or may not be both the CEO of Megaspeed and an associated company called “Shanghai Hexi,” which is also owned by the Yangtze River Delta project… who was also photographed sitting next to Jensen Huang at an event in Taipei in 2024.
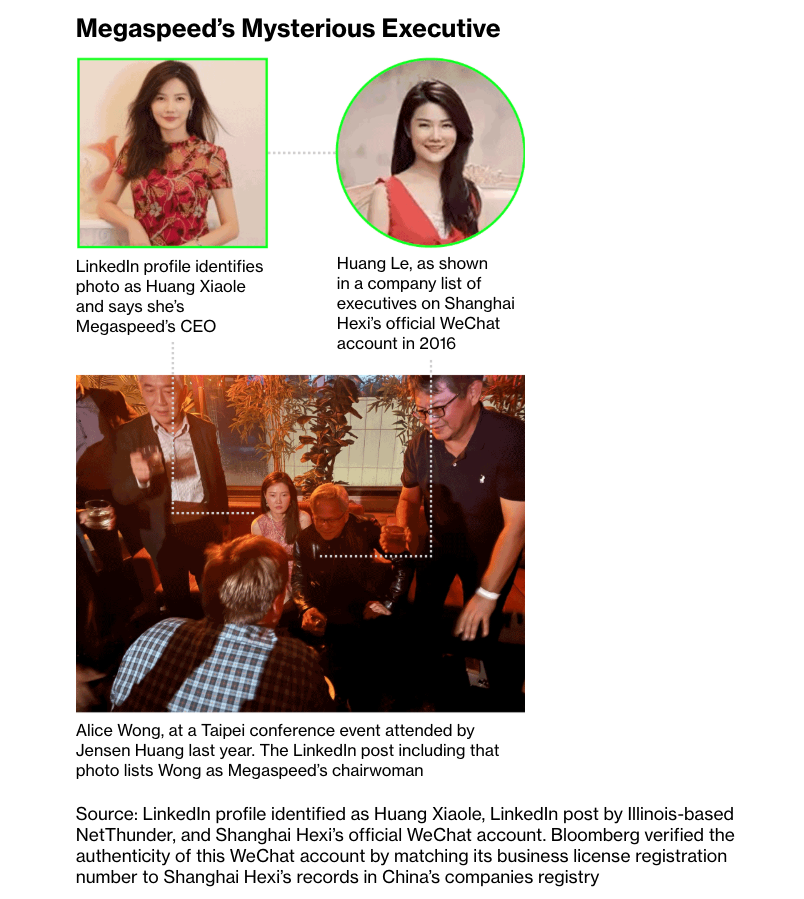
While all of this is extremely weird and suspicious, I must be clear there is no declarative answer as to what’s going on, other than that NVIDIA GPUs are absolutely making it to China, somehow. I also think that it would be really tough for Jensen Huang to not know about it, or for billions of dollars of GPUs to be somewhere without NVIDIA’s knowledge.
Anyway, Supermicro CEO Charles Liang has yet to comment on Wally Liaw or his alleged co-conspirators, other than a statement from the company that says that their acts were “a contravention of the Company’s policies and compliance controls.”
Jensen Huang does not appear to have been asked if he knew anything about this — not Megaspeed, not Supermicro, or really any challenging question of any kind for the last few years of his life.
Huang did, however, say back in May 2025 that there was “no evidence of any AI chip diversion,’ and that the countries in question “monitor themselves very carefully.”
For legal reasons I am going to speak very carefully: I cannot say that Jensen is wrong, or lying, but I think it’s incredible, remarkable even, that he had no idea that any of this was going on. Really? Hundreds of millions if not billions of dollars of GPUs are making it to China — as reported by The Information in December 2025 — and Jensen Huang had no idea? I find that highly unlikely, though I obviously can’t say for sure.
In the event that NVIDIA had knowledge — which I am not saying it did, of course — this is a huge scandal that, for the most part, nobody has bothered to keep an eye on outside of a few brave souls at The Information and Bloomberg who give a shit about the truth. Has anybody bothered to ask Jensen about this? People talk to him on camera all the time.
Sidenote: Earlier today, US Senators Jim Banks and Elizabeth Warren issued a letter to Howard Lutnick, Trump' s Commerce Secretary, demanding the Department of Commerce take “all necessary and appropriate actions” to stop the flow of NVIDIA chips to China, including potentially block exports to countries believed to be intermediaries, like Malaysia, Thailand, Vietnam, and Singapore.
The arrest of Liaw has, it seems, ruffled some feathers in Washington, and I would not be shocked to see Huang sat before a congressional inquiry at some point.
I’ll also add that I am shocked that so many people are just shrugging and moving on from Supermicro, which is a major supplier of two of the major neoclouds (Crusoe and CoreWeave) and one of the minors (Lambda, which they also rents cloud capacity to). The idea that a company had no idea that several percentage points of its revenue were flowing directly to China via one of its co-founders is an utter joke.
I hope we eventually find out the truth. Nevertheless, this kind of underhanded bullshit is a sign of desperation on the part of just about everybody involved.
The End of Software Engineering — Hyperscalers Are Forcing AI On Their Workers, Destroying The Quality Of Their Products, and Crashing Their Services
So, I want to explain something very clearly for you, because it’s important you understand how fucked up shit has become: hyperscalers are forcing everybody in their companies to use AI tools as much as possible, tying compensation and performance use to token burn, and actively encouraging non-technical people to vibe-code features that actually reach production.
In practice, this means that everybody is being expected to dick around with AI tools all day, with the expectation that you burn massive amounts of tokens and, in the case of designers working in some companies, actively code features without ever knowing a line of code.
“How do I know the last part? Because a trusted source told me — and I’ll leave it at that”
One might be forgiven for thinking this means that AI has taken a leap in efficacy, but the actual outcomes are a labyrinth of half-functional internal dashboards that measure random user data or convert files, spending hours to save minutes of time at some theoretical point. While non-technical workers aren’t necessarily allowed to ship directly to production, their horrifying pseudo-software, coded without any real understanding of anything, is expected to be “fixed” by actual software engineers who are also expected to do their jobs.
These tools also allow near-incompetent Business Idiot software engineers to do far more damage than they might have in the past. LLM use is relatively-unrestrained (and actively incentivized) in at least one hyperscaler, with just about anybody allowed to spin up their own OpenClaw “AI agent” (read: series of LLMs that allegedly can do stuff with your inbox or Slack for no clear benefit, other than their ability to delete all of your emails). In Meta’s case, this ended up causing a severe security breach:
According to internal Meta communications and an incident report seen by The Information, a major security alert occurred last week after a Meta software engineer used an in-house agent tool, similar to OpenClaw, to analyze a technical question that another Meta employee had posted on an internal discussion forum. After doing the analysis, the AI agent posted a response in the discussion forum to the original question, offering advice on the technical issue, according to internal communications. The agent did so without approval from the employee.
According to The Information, Meta systems storing large amounts of company and user-related data were accessible to engineers who didn’t have permission to see them, and was marked a sec-1 incident, the second highest level of severity on an internal scale that Meta uses to rank security incidents.
The incident follows multiple problems caused at Amazon by its Kiro and Q LLMs. I quote Business Insider’s Eugene Kim:
On March 2, customers across Amazon marketplaces saw incorrect delivery times when adding items to their carts. The incident led to nearly 120,000 lost orders and roughly 1.6 million website errors. Amazon's AI tool Q was one of the primary contributors that triggered the event, according to an internal review.
On March 5, another outage caused a 99% drop in orders across Amazon's North American marketplaces, resulting in 6.3 million lost orders, one of the internal documents stated. One key factor was a production change that was deployed without using a formal documentation and approval process called Modeled Change Management.
LLMs Are Destroying Big Tech From The Inside
Despite the furious (and exhausting) marketing campaign around “the power of AI code,” I believe that these events are just the beginning of the true consequences of AI coding tools: the slow destruction of the tech industry’s software stack.
LLMs allow even the most incompetent dullard to do an impression of a software engineer, by which I mean you can tell it “make me software that does this” or “look at this code and fix it” and said LLM will spend the entire time saying “you got this” and “that’s a great solution.”
The problem is that while LLMs can write “all” code, that doesn’t mean the code is good, or that somebody can read the code and understand its intention (as these models do not think), or that having a lot of code is a good thing both in the present and in the future of any company built using generative code.
LLM-based code is often verbose, and rarely aligns with in-house coding guidelines and standards, guaranteeing that it’ll take far longer to chew through, which naturally means that those burdened with reviewing it will either skim-read it or feed it into another LLM to work out what the hell to do.
Worse still, LLM use is also entirely directionless. Why is anybody at Meta using an OpenClaw? What is the actual thing that OpenClaw does, other than burn an absolute fuck-ton of tokens?
Think about this very, very simply for a second: you have given every engineer in the company the explicit remit to write all their code using LLMs, and incentivized them to do so by making sure their LLM use is tracked. You have now massively increased both the operating costs of the company (through token burn costs) and the volume of code being created.
To be explicit, allowing an LLM to write all of your code means that you are no longer developing code, nor are you learning how to develop code, nor are you going to become a better software engineer as a result. This means that, across almost every major tech company, software engineers are being incentivized to stop learning how to write software or solve software architecture issues.
If you are just a person looking at code, you are only as good as the code the model makes, and as Mo Bitar recently discussed, these models are built to galvanize you, glaze you, and tell you that you’re remarkable as you barely glance at globs of overwritten code that, even if it functions, eventually grows to a whole built with no intention or purpose other than what the model generated from your prompt.
Things only get worse when you add in the fact that hyperscalers like Meta and Amazon love to lay off thousands of people at a time, which makes it even harder to work out why something was built in the way it was built, which is even harder when an LLM that lacks any thoughts or intentions builds it. Entire chunks of multi-trillion dollar market cap companies are being written with these things, prompted by engineers (and non-engineers!) who may or may not be at the company in a month or a year to explain what prompts they used.
We’re already seeing the consequences! Amazon lost hundreds of thousands of orders! Meta had a major security breach! The foundations of these companies are being rotted away through millions of lines of slop-code that, at best, occasionally gets the nod from somebody who has “software engineer” on their resume, and these people keep being fired too, raising the likelihood that somebody who knows what’s going on or why something is built a certain way will be able to stop something bad from happening.
Remember: Google, Amazon, Microsoft, and Meta all hold vast troves of personal information, intimate conversations, serious legal documents, financial information, in some cases even social security numbers, and all four of them along with a worrying chunk of the tech industry are actively encouraging their software engineers to stop giving a fuck about software.
Oh, you’re so much faster with AI code? What does that actually mean? What have you built? Do you understand how it works? Did you look at the code before it shipped, or did you assume that it was fine because it didn’t break?
This is creating a kind of biblical plague within software engineering — an entire tech industry built on reams of unmanageable and unintentional code pushed by executives and managers that don’t do any real work. LLMs allow the incompetent to feign competence and the unproductive to produce work-adjacent materials borne of a loathing for labor and craftsmanship, and lean into the worst habits of the dullards that rule Silicon Valley.
All the Valley knows is growth, and “more” is regularly conflated with “valuable.” The New York Times’ Kevin Roose — in a shocking attempt at journalism — recently wrote a piece celebrating the competition within Silicon Valley to burn more and more tokens using AI models:
An engineer at OpenAI processed 210 billion “tokens” — enough text to fill Wikipedia 33 times — through the company’s artificial intelligence models over the last week, the most of any employee. At Anthropic, a single user of the company’s A.I. coding system, Claude Code, racked up a bill of more than $150,000 in a month.
And at tech companies like Meta and Shopify, managers have started to factor A.I. use into performance reviews, rewarding workers who make heavy use of A.I. tools and chastening those who don’t.
This is the new reality for coders, some of the first white-collar workers to feel the effects of A.I. as it sweeps through the economy. A.I. was supposed to help tech companies boost productivity and cut costs. But it has also created an expensive new status game, known as “tokenmaxxing,” among A.I.-obsessed workers who are desperate to prove how productive they are.
Roose explains that both Meta and OpenAI have internal leaderboards that show how many tokens you’ve used, with one software engineer in Stockholm spending “more than his salary in tokens,” though Roose adds that his company pays for them.
Roose describes a truly sick culture, one where OpenAI gives awards to those who spend a lot of money on their tokens, adding that he spoke with several tech workers who were spending thousands of dollars a day on tokens “for what amount to bragging rights.” Roose also added one more insane detail: that one person found a loophole in Claude’s $20-a-month using a piece of software made by Figma that allowed them to burn $70,000 in tokens.
Despite all of this burn, Roose struggled to find anybody who was able to explain what they were doing beyond “maintaining large, complex pieces of software using coding agents running in parallel,” but managed to actually find one particularly useful bit of information — that all of this might be performative:
They said, by and large, that A.I. coding tools were making them more productive. But some also framed their use of A.I. as a strategic move — a way to signal, to their colleagues and bosses, that they’re keeping up with the times, as the era of human coding appears to be coming to an end.
I do give Roose one point for wondering if “...any of these tokenmaxxers [were] producing anything good, or whether they [were] merely spinning their wheels churning out useless code in an attempt to look busy.” Good job Kevin.
That being said, I find this story horrifying, and veering dangerously close to the actions of drug addicts and cult followers. Throughout this story in one of the world’s largest newspapers, Roose fails to find a single “tokenmaxxer” making something that they can actually describe, which has largely been my experience of evaluating anyone who talks nonstop about the power of “agentic coding.”
These people are sick, and are participating in a vile, poisonous culture based on needless expenses and endless consumption.
Companies incentivizing the amount of tokens you burn are actively creating a culture that trades excess for productivity, and incentivizing destructive tendencies built around constantly having to find stuff to do rather than do things with intention. They are guaranteeing that their software will be poorly-written and maintained, all in the pursuit of “doing more AI” for no reason other than that everybody else appears to be doing so.
Anybody who actually works knows that the most productive-seeming people are often also the most-useless, as they’re doing things to seem productive rather than producing anything of note. A great example of this is a recent Business Insider interview with a person who got laid off from Amazon after learning “AI” and “vibe coding,” and how surprised they were that these supposed skills didn’t make them safer from layoffs:
At the time of the October layoffs, there was debate around whether AI was the reason.
The company was encouraging us to use AI at the time, but I don't think it took my job. I wrote descriptions for internal products at Amazon, and when I used AI to help, I'd need to ask it to rewrite its output without fluff words. It didn't sound like how people talk. Despite my ethical qualms, I used AI, but, in my opinion, it was nowhere close to replacing my role. Before I was laid off, I helped build an internal site for Amazon using AI. I hadn't really coded before, but with a colleague's help, I learned how to vibe code with a lot of trial and error.
I thought using AI for this project and showcasing different skills would make me more valuable to the company, but in the end, it didn't keep me from being laid off.
To be clear, this person is a victim. They were pressured by Amazon to take up useless skills and build useless things in an expensive and inefficient way, and ended up losing their job despite taking up tools they didn’t like under duress.
Sidenote: If you read that sentence and suggest that she should’ve used AI better, you are a mark. You are being conned into an unpaid marketing job for AI companies that actively hate you.
This person was, at one point, actively part of building an internal Amazon site using AI, and had to “learn to vibe code with a lot of trial and error” and the help of a colleague. Was this a good use of her time? Was this a good use of her colleague’s time?
No! In fact, across all of these goddamn AI coding hype-beast Twitter accounts and endless proclamations about the incredible power of AI agents, I can find very few accounts of something happening other than someone saying “yeah I’m more productive I guess.”
I am certain that at some point in the near future a major big tech service is going to break in a way that isn’t immediately fixable as a result of thousands of people building software with AI coding tools, a problem compounded by the dual brain drain forces of layoffs and a culture that actively empowers people to look busy rather than actually produce useful things.
What else would you expect? You’re giving people a number that they can increase to seem better at their job, what do you think they’re going to do, try and be efficient? Or use these things as much as humanly possible, even if there really isn’t a reason to?
I haven’t even gotten to how expensive all of this must be, in part because it’s hard to fully comprehend.
But what I do know is that big tech is setting itself up for crisis after crisis, especially when Anthropic and OpenAI stop subsidizing their models to the tune of allowing people to spend $2500 or more on a $200-a-month subscription.
What happens to the people who are dependent on these models? What happens to the people who forgot how to do their jobs because they decided to let AI write all of their code? Will they even be able to do their jobs anymore?
Large Language Models are creating Silicon Valley Habsburgs — workers that are intellectually trapped at whatever point they started leaning on these models that were subsidized to the point that their bosses encouraged them to use them as much as humanly possible. While they might be able to claw their way back into the workforce, a software engineer that’s only really used LLMs for anything longer than a few months will have to relearn the basic habits of their job, and find that their skills were limited to whatever the last training run for whatever model they last used was.
I’m sure there are software engineers using these models ethically, who read all the code, who have complete industry over it and use it as a means of handling very specific units of work that they have complete industry over.
I’m also sure that there are some that are just asking it to do stuff, glancing at the code and shipping it. It’s impossible to measure how many of each camp there are, but hearing Spotify’s CEO say that its top developers are basically not writing code anymore makes me deeply worried, because this shit isn’t replacing software engineering at all — it’s mindlessly removing friction and putting the burden of “good” or “right” on a user that it’s intentionally gassing up.
Ultimately, this entire era is a test of a person’s ability to understand and appreciate friction.
Friction can be a very good thing. When I don’t understand something, I make an effort to do so, and the moment it clicks is magical. In the last three years I’ve had to teach myself a great deal about finance, accountancy, and the greater technology industry, and there have been so many moments where I’ve walked away from the page frustrated, stewed in self-doubt that I’d never understand something.
I also have the luxury of time, and sadly, many software engineers face increasingly-deranged deadlines set by bosses that don’t understand a single fucking thing, let alone what LLMs are capable of or what responsible software engineering is. The push from above to use these models because they can “write code faster than a human” is a disastrous conflation of “fast” and “good,” all because of flimsy myths peddled by venture capitalists and the media about “LLMs being able to write all code.”
Generative code is a digital ecological disaster, one that will take years to repair thanks to company remits to write as much code as fast as possible.
Every single person responsible must be held accountable, especially for the calamities to come as lazily-managed software companies see the consequences of building their software on sand.
The Tech Industry Has Poisoned Itself With The Lies of AI
In the end, everything about AI is built on lies.
Hundreds of gigawatts of data centers in development equate to 5GW of actual data centers in construction.
Hundreds of billions of dollars of GPU sales are mostly sitting waiting for somewhere to go.
Anthropic’s constant flow of “annualized” revenues ended up equating to literally $5 billion in revenue in four years, on $25 billion or more in salaries and compute.
Despite all of those data centers supposedly being built, nobody appears to be making a profit on renting out AI compute.
AI’s supposed ability to “write all code” really means that every major software company is filling their codebases with slop while massively increasing their operating expenses. Software engineers aren’t being replaced — they’re being laid off because the software that’s meant to replace them is too expensive, while in practice not replacing anybody at all.
Looking even an inch beneath the surface of this industry makes it blatantly obvious that we’re witnessing one of the greatest corporate failures in history. The smug, condescending army of AI boosters exists to make you look away from the harsh truth — AI makes very little revenue, lacks tangible productivity benefits, and seems to, at scale, actively harm the productivity and efficacy of the workers that are being forced to use it.
Every executive forcing their workers to use AI is a ghoul and a dullard, one that doesn’t understand what actual work looks like, likely because they’re a lazy, self-involved prick.
Every person I talk to at a big tech firm is depressed, nagged endlessly to “get on board with AI,” to ship more, to do more, all without any real definition of what “more” means or what it contributes to the greater whole, all while constantly worrying about being laid off thanks to the truly noxious cultures that are growing around these services.
AI is actively poisonous to the future of the tech industry. It’s expensive, unproductive, actively damaging to the learning and efficacy of its users, depriving them of the opportunities to learn and grow, stunting them to the point that they know less and do less because all they do is prompt. Those that celebrate it are ignorant or craven, captured or crooked, or desperate to be the person to herald the next era, even if that era sucks, even if that era is inherently illogical, even if that era is fucking impossible when you think about it for more than two seconds.
And in the end, AI is a test of your introspection. Can you tell when you truly understand something? Can you tell why you believe in something, other than that somebody told you you should, or made you feel bad for believing otherwise? Do you actually want to know stuff, or just have the ability to call up information when necessary?
How much joy do you get out of becoming a better person?If you can’t answer that question with certainty, maybe you should just use an LLM, as you don’t really give a shit about anything.
And in the end, you’re exactly the mark built for an AI industry that can’t sell itself without spinning lies about what it can (or theoretically could) do.
