
Hi! If you like this piece and want to support my work, please subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5000 to 185,000 words, including vast, extremely detailed analyses of NVIDIA, Anthropic and OpenAI’s finances, and the AI bubble writ large.
I just put out a massive Hater’s Guide To The SaaSpocalypse — an urgent and in-depth analysis of the end of the hypergrowth era of software — and my Hater’s Guides To Private Equity, Anthropic, Oracle and Microsoft are huge (12k+ word) research projects priced lower than the cost of a cup of coffee, which is partly an inflation issue on the part of the coffee shop, but what I’m getting at is this is a ton of value.
Where’s Your Ed At Premium is incredibly useful, read by hedge funds, private equity firms, Fortune 500 CEOs, a large chunk of the business and tech media, and quite a few CEOs of major tech firms. I am regularly several steps ahead in my coverage, and you get an absolute ton of value, several books’ worth of content a year. Subscribe today and support my work, I deeply appreciate it.
Small Editor's Note: the original email said "Matthew Hughes" because he uploads it to Ghost and formats it for me. Sorry!
Hey everyone! I know everybody is super excited about the supposed power of AI, but I think it’s time we set some fair ground rules going forward so we stop acting so crazy.
Let’s start with a simple one: AI boosters are no longer allowed to explain what’s good about AI using the future tense. You can no longer say “it will,” “could,” “might,” “likely,” “possible,” “estimated,” “promise,” or any other term that reviews today’s capabilities in the language of the future.
I am constantly asked to explain my opinions (not that anybody who disagrees with me actually reads them) in the terms of the present, I am constantly harangued for proof of what I believe, and every time I hand it over there’s some sort of ham-fisted response of “it’s getting better” and “it will get even more better from here!’
That’s no longer permissible! I am no longer accepting any arguments that tell me something will happen, or that “things are trending” in a certain way. For an industry so thoroughly steeped in cold, hard rationality, AI boosters are so quick to jump to flights of fancy — to speak of the mythical “AGI” and the supposed moment when everything gets cheaper and also powerful enough to be reliable or effective.
I hear all this crap about AI changing everything, but where’s the proof?
Wow. Anthropic managed to turn $30 billion dollars into $5 billion dollars and start one of the single most annoying debates in internet history. No, really, its CFO Krishna Rao stated on March 9, 2026 in a legal filing that it had made “exceeding” $5 billion in revenue and spent “over” $10 billion on inference and training. None of these numbers line up with previous statements about annualized revenue, by the way — I went into this last week — and no amount of contorting around the meaning of “exceeding” takes away from the fact that adding up all the annualized revenues is over $6 billion, which I believe means that Anthropic defines “annualized” in a new and innovative way.
In any case, Anthropic turned $30 billion into $5 billion. That’s…bad. That’s just bad business. And I hear no compelling argument as to how this might improve, other than “these companies need more compute, and then something will happen.”
In fact, let’s talk about that for a second. At the end of January, OpenAI CFO Sarah Firar said that “our ability to serve customers—as measured by revenue—directly tracks available compute,” messily suggesting that the more compute you have the more revenue you have.
This is, of course, a big bucket of bollocks. Did OpenAI scale its compute dramatically between hitting $20 billion in annualized revenue (to be clear, I have deep suspicions about these numbers and how OpenAI measures “annualized” revenue) in January 2026 and $25 billion in March 2026? I think that’s highly unlikely.
I also have to ask — where are the limited parties, exactly? If revenue scales with revenue, wouldn’t that mean that each increase in compute availability would be allowing somebody to pay OpenAI or Anthropic that couldn’t do so before? I don’t see any reports of customers who can’t pay either company due to a lack of available compute. Are there training runs that can’t be done right now? That doesn’t really make sense either, because training doesn’t automatically lead to more revenue, other than in releasing a new model, I guess?
It’s almost as if every talking point in the generative AI industry is the executives in question saying stuff in the hopes that people will just blindly repeat it!
Please Stop Comparing Generative AI To Uber
But really folks, we’ve gotta start asking: where’s the money?
Anthropic made $5 billion in its entire existence in revenue and spent $10 billion just on compute. OpenAI claims it made $13.1 billion in revenue in 2025 and “only” lost $8 billion — but those numbers seem unlikely considering my report from November of last year that had OpenAI at $4.3 billion in revenue on $8.67 billion of inference costs through September 2025, and this is accrual accounting, which means these are from the quarters in question. How likely do you think it is that OpenAI booked $8.8 billion in a quarter (Q4 CY2025) and only lost $8 billion in the year after it lost $12 billion (per the Wall Street Journal) in the previous quarter?
Look, I get it! This isn’t a situation where thinking critically is rewarded. Even articles explicitly criticizing the economics of these companies are still filled with weasel wording about “expects to grow” and “anticipates hitting,” or the dreaded phrase “if their bet pays off.” Saying obvious stuff like “every AI company is unprofitable” or “there is no path to profitability” or “nobody is talking about AI revenues” is considered unfair or cynical or contrarian, even though these are very reasonable and logical statements grounded in reality.
“But Ed! What about Uber!”
What about Uber? Uber is a completely different business to Anthropic and OpenAI or any other AI company. It lost about $30 billion in the last decade or so, and turned a weird kind of profitable through a combination of cutting multiple markets and business lines (EG: autonomous cars), all while gouging customers and paying drivers less.
The economics are also completely different. Uber does not pay for its drivers’ gas, nor their cars, nor does it own any vehicles. Its PP&E has been between $1.5 billion and $2.1 billion since it was founded. Uber’s revenue does not increase with acquisitions of PP&E, nor does its business become significantly more expensive based on how far a driver drives, how many passengers they might have in a day, or how many meals they might deliver. Uber is, effectively, a digital marketplace for getting stuff or people moved from one place to another, and its losses are attributed to the constant need to market itself to customers for fear that other rideshare (Lyft) or delivery companies (DoorDash, Seamless) might take its cash.
Also: Uber’s primary business model was on a ride-by-ride basis, not a monthly subscription. Users may have been paying less, but they were still thinking about each transaction with Uber in terms that made sense when prices were raised (though it briefly tried an unlimited ride pass option in 2016).
Charging on a ride-by-ride basis was the smartest move that Uber made, as it meant that when prices went up, users didn’t have to change their habits.
AI companies make money either through selling subscriptions (or some sort of token-based access to a model) or by renting their models out via their APIs. One of their biggest mistakes was offering any kind of monthly subscription to their services, because the compute cost of a user is almost impossible to reconcile with any amount they’d pay a month, as the exponential complexity of a task is impossible to predict, both based on user habits and the unreliability of an AI model in how it might try and produce an output.
Let’s give an example. Somebody spending $20 a month on a Claude subscription can spend as much as $163 in compute.
There are two reasons this might be happening:
- Anthropic is intentionally subsidizing its subscribers’ compute in an attempt to gain market share.
- Anthropic is incapable of creating stable limitations on its models’ compute costs, as Large Language Models cannot be “limited” in a linear sense to “only spend” a certain amount of tokens, as it’s impossible to guarantee how many tokens a task might take.
- While I must be clear that Anthropic can limit Claude subscriptions, as can OpenAI limit ChatGPT, I doubt either can do so with precision.
In both cases, Anthropic (and OpenAI, for that matter) is screwed. If we assume Anthropic’s gross margin is 38% (per The Information, though to be clear I no longer trust any leak from Anthropic, also no, Dario did not say Anthropic had 50% gross margins, it was a hypothetical), that would mean that $163 of compute costs it $101. Now, not every user is spending that much, but I imagine a lot of users are considering the aggressive (and deceptive) media campaign around Claude Code means that a great many are, at the very least, testing the limits of the product. Those on the Max $100 and $200-a-month plans are specifically paying for fewer rate limits, meaning that they are explicitly paying to burn more tokens.
The obvious argument that you could make is that Anthropic could simply increase the price of the subscription product, but I need to be clear that for any of this to make sense, it would have to do so by at least 300%, and even then that might not do the job. This would immediately price out most consumers — an $80-a-month subscription would immediately price out just about every consumer, and turn this from a “kind of like the cost of Netflix” purchase into something that has to have obvious, defined results. A $400-a-month or $800-a-month subscription would make a Claude or ChatGPT Pro subscription the size of a car payment. For a company with 100 engineers, a subscription to Claude Max 5x would run at around $480,000 a year.
And this is assuming that rate limits stay the same, which I doubt they would.
In any case, there is no future for any AI company that uses a subscription-based approach, at least not one where they don’t directly pass on the cost of compute.
This is a huge problem for both Anthropic and OpenAI, as their scurrilous growth-lust means that they’ve done everything they can to get customers used to paying a single monthly cost that directly obfuscates the cost of doing business.
I need to be very direct about what this means, because it’s very important and rarely if ever discussed.
A user of ChatGPT or Claude Code is only thinking of “tokens” or “compute” in the most indirect sense — a vague awareness of the model using something to do something else, totally unmoored from the customer’s use of the product. All they see is the monthly subscription cost ($20, $100, or $200-a-month) and rate limits that vaguely say you have X% of your five-hour allowance left. Users are not educated in (nor are they thinking about) their “token burn” or burden on the company, because software has basically never made them do so in the past.
This means it will be very, very difficult to increase subscription costs on users, and near-impossible to convince them to pay the cost of the API. It’s like if Uber, which had charged $20-a-month for unlimited rides, suddenly started charging users their drivers’ gas costs, and gas was at around $250 a gallon.
That might not even do the price disparity justice. This theoretical example still involves users being in the back of a car and being driven a distance, and that said driving costs gas. Token burn is an obtuse, irregular process involving a per-million input and output tokens, with the latter increasing when you use reasoning models, which use output tokens to break down how it might handle a task.
The majority of AI users do not think in these terms, and even technical users that do so have likely been using a monthly subscription which doesn’t make them think about the costs. Think about it — you log onto Claude Code every day and do all your work on it, sometimes bumping into rate limits, then coming back five hours (or however long) later and doing the same thing. Perhaps you’re thinking that a particular task might burn more tokens, or that you should use a model like Claude Sonnet over Claude Opus so that you don’t hit your limits earlier, but you do not, in most cases, even if you know the costs of a model, think about them in a way that’s useful.
Let’s say that Anthropic and OpenAI immediately decide to switch everybody to the API. How would anybody actually budget? Is somebody that pays $200 a month for Claude Max going to be comfortable paying $1000 or $1500 or $2500 a month in costs, and have, at that point, really no firm understanding of the cost of a particular action?
First, there’s no way to anticipate how many tokens a prompt will actually burn, which makes any kind of budgeting a non-starter. It’s like going to the supermarket and committing to buy a gallon of milk, not knowing if it’ll cost you $5 or $50.
But also, suppose a prompt doesn’t quite return the result you need, and thus, you’re forced to run it again — perhaps with slightly altered phrasing, or with more exposition to ensure the model has every detail you need. And again, you have no idea how many tokens the model will burn. How does a person budget for that kind of thing?
This is a problem both based on user habits and the unreliability of Large Language Models — such as spending several minutes “thinking” when they get stuck in loops trying to evaluate code or come up with a way to execute a task.
User habits are also antithetical to switching from a paid subscription to metered access to models. A user might forgive Claude for chasing its own tail for several minutes when not burdened by the cost of it doing so, but if that act cost $2 or $3 or $10, they may hesitate to use the model at all.
I’ll give you another example. You, a relative novice, decide to use Claude Code to build a dinky little personal website. During the process, Claude Code gets lost, messes up a few little things, taking a few minutes in aggregate, and you calmly tell it to fix things and do what you’d like, and after a little back-and-forth you get something you’re happy with. As you try and upload it to Amazon Web Services, you get stuck, and spend ten minutes getting it to explain how you get the website online.
At $20 a month, you might find this process delightful, empowering even. You just coded a website (even if it was a clone of one of thousands of different online templates), and you did so using natural language. Wow! What a magical world we live in. You realize as you look at the website that you forgot to add a section. Doing so takes another half an hour. You bump into your rate limits, take a break for five hours, then come back and finish it at the end of the day. The model has told you the entire time that you’re a genius for making this, and the website rocks, and that you built it, even though you didn’t.
If you were paying via the API, this excursion could’ve cost you anywhere from $5 to $15. Every single little back-and-forth begins to add up. Every little change. Every little addition. Every attempt that Claude makes to fix something but makes it worse. Every “I don’t get it” you feed it about AWS.
It’s difficult to actually say what it was that made it expensive or not, and doing so adds a level of cognitive burden on top of the constant vigilance you need to make sure the model doesn’t do something unproductive. Even explicit, direct and well-manicured prompts can lead these models on expensive little expeditions.
Token burn isn’t something that neatly maps to another way that we pay for things outside of cloud storage, and even then, there are very few services that rival the chaotic costs of Large Language Models. Even if people can conceptualize that there are inputs and outputs, the latter of which costs more money, mapping a task to a reliable amount of tokens is actually pretty difficult.
Even if these companies were profitable on inference (I do not believe they are), they are dramatically, horrendously unprofitable on subscriptions, and there isn’t a chance in Hell that the majority of those subscriptions convert into token-based API users.
When Uber — a completely different business, to be clear — jacked up prices, it did so gradually, and also didn’t ask users to dramatically shift how they think about using the app.
Anthropic and OpenAI have no clean way to jack up prices or cut costs. They can increase subscription fees, but doing so would lead to users paying two to five times what they’re paying today, which would undoubtedly lead to massive churn.
They could also reduce rate limits with the intention of pushing people toward the API, but as I’ve discussed, subscription-based customers are neither educated nor prepared to pay a confusing, metered service that directly counters habits driven by an abundance of token burn. Users are not taught to be considerate of their burn or mindful of their costs when using a subscription-based LLM.
The other problem is that these companies don’t really appear to have a way to cut costs, because inference remains very expensive and training costs are never going away:
Training is, for an AI lab like OpenAI and Anthropic, as common (and necessary) a cost as those associated with creating outputs (inference), yet it’s kept entirely out of gross margins. To quote The Information: “Anthropic has previously projected gross margins above 70% by 2027, and OpenAI has projected gross margins of at least 70% by 2029, which would put them closer to the gross margins of publicly traded software and cloud firms. But both AI developers also spend a tremendous amount on renting servers to develop new models—training costs, which don’t factor into gross margins—making it more difficult to turn a net profit than it is for traditional software firms.
This is inherently deceptive [on the part of Anthropic]. While one would argue that R&D is not considered in gross margins, training isn’t gross margins — yet gross margins generally include the raw materials necessary to build something, and training is absolutely part of the raw costs of running an AI model. Direct labor and parts are considered part of the calculation of gross margin, and spending on training — both the data and the process of training itself — are absolutely meaningful, and to leave them out is an act of deception.
I hear a lot of wank about “ASICs” and “TPUs” that will magically bring down costs. When? How? Oh, NVIDIA’s latest chip is 10x more efficient or some bullshit? Show me the fucking evidence! Because every time the revenues and costs get reported the revenues seem lower and the costs seem higher.
And it’s completely fucking insane that we don’t have an answer beyond “things will get cheaper” or “prices will go up.” Despite everybody talking about it endlessly for three god damn years, LLMs lack the kind of obvious, replicable, industrially-necessary outcomes that make a 3x, 4x or 10x price increase tenable.
I also think that Anthropic and OpenAI have deliberately used their subscriptions as a means of conning the media into conceptualizing AI as far more affordable than it actually is. Most users do not have any real idea of how much it costs to use these services, let alone how much it costs to run them.
All of that glowing, effusive press around Claude Code was based on outcomes that were both subsidized and obfuscated by Anthropic. I think that these articles would’ve been much less positive if the reporters were even aware of the actual costs.
Most AI Users — Especially Coders — Are Unprepared For The Cost Of Paying For Their Actual Token Burn
So, let’s do some maths shall we?
Assume a business has 100 engineers, and currently pays $200 a month for each engineer to use Claude Max, at a cost of $20,000 a month, or $240,000 a year. Let’s assume on average you pay your engineers $125,000, meaning that your salaries are $12.5 million a year, not considering other costs (this is a toy example).
Now imagine that Claude switches to a metered billing system.
Let’s assume that, in actuality, these engineers are burning a mere $10 a day in tokens, which brings costs to $365,000 a year, or an increase of $125,000…and remember, this is a team of engineers that were previously used to a subscription that allowed them to spend upwards of $2700 a month in tokens, or nearly 10 times the $300 a month they’re now spending.
Let’s be a little more realistic, and bump that number up to $25. Now you’re spending $912,500 a year in tokens. $30 a day puts you over a million bucks. Oops, busy month, you’re now spending $40 a day. Now you’re spending more than 10% of your salaries on compute costs.
Anthropic’s own Claude Code documentation says that the average cost is $6 per-developer-per-day, with “daily costs remaining below $12 for 90% of users.” Good news! If you, as an engineer, can limit your usage to $6 a day, you’re actually saving the company money!
But you’re not spending $6 a day. That’s a silly number for anybody coding. One user on Reddit said that they spent $200-to-300 a day on API costs and decided instead to spend $40 to $50 a day on a GPU cluster on Lambda to use the open source model Qwen 3.5 to handle their code, which still works out at $14,600 in API costs.
Another user found that their parallel Claude Code sessions using Claude’s $200-a-month plan (I assume using multiple accounts) worked out to around $12,000 a month in API costs. Another that hit their limits on their Max subscription “only needed another hour or two to finish a project,” and that hour or two resulted in almost $600 in API costs.
Even the boosters are beginning to worry. Last week, Chamath Palihapitiya made a shockingly reasonable point:
Not a single meaningful company has yet to say that they are making at least 2x+ from all of this incremental money they are spending since even last Fall! When ROI?
When ROI indeed, Chamath. The fact that one of the most-prominent voices (for better or worse) in the tech industry is unable to get a straight answer to “where is the return on investment” — somebody directly incentivized to keep the party going — should have everybody a little worried.
AI’s Economics Have Never Made Sense, And The ROI Is MIA
Really though, where is the ROI?
Who is actually getting a profit out of this? NVIDIA? The companies that make RAM? Because it doesn’t seem to be the companies who are buying the GPUs. It doesn’t seem to be the AI companies. I don’t think it’s true, but if you believe it, you believe code is truly being automated away — to what end? What are the actual documented economic effects we can point at and what are the actual meaningful changes to the world?
Real data. Something from today, please. You are legally banned from saying the words “soon” or “in the future.” No more future-tense. It’s not allowed. All of my stuff has to be in the present — so yours should too.
Let’s do a quick-fire round:
- Hyperscalers are seeing incredible revenue growth, which is coming from AI!- why aren’t they telling us their AI revenues, then? Also, every single hyperscaler has hiked prices in the last few years, with Microsoft’s latest increases including a 33% increase on cheap subscriptions for front-line workers.
- Fun fact! Microsoft was the only hyperscaler to ever talk about actual AI revenues, and last did so in January 2025 when it said it had reached a “$13 billion run rate” (so $1.03 billion). It has never done so again.
- We’re in the early day- shut up. Stop it. We’re nearly four years in. What’re you talking about?
- The exponential growth in capabilities of AI models- I am calling Jigsaw from “Saw” if you cannot express to me in clear, certain and direct terms what it is that’s actually changed. No benchmarks, either! They had to stop using SWE-Bench because models were trained specifically to solve it. Show me something that an LLM created, all on its own, and it better be fucking great, and fast too.
- Oh it “sped up coders”? How? To what end? Is the code better? Did they lay people off?
- Block laid off 4000 people because of AI- Yes hello, Mr. Jigsaw? Yeah it’s Ed, you had me chained against a radiator the other week. No, I’m doing a lot better, I’m glad we talked things out. Anyway, I need your help with something. Everybody is saying that Block laid off 4000 people because of AI, and that proves something! All Jack Dorsey said was that “[Block is] already seeing that the intelligence tools [it’s] creating and using…are enabling a new way of working which fundamentally changes what it means to build and run a company.” I know, that doesn’t mean anything, and all Block is doing is AI-washing, which is when a company uses AI as a scapegoat to justify laying people off. No, no, don’t handcuff anyone to a radiator, I just needed somebody to talk to. Maybe later, okay?
- Jokes aside, Block — like many other companies — aggressively recruited during the pandemic, with headcount growing by 2.5x between 2019 and 2025. And now, as the market conditions are looking choppier, it seems like it’s trying to Ozempic away some of its corporate “bloat.”
- Saying you’re firing people because of AI is a bit less embarrassing than saying “we fucked up.”
- [Software company] is still growing, so AI must be helping?- Is that actually true? Have you looked? Because if you haven’t looked, I wrote about this in the Hater’s Guide To The SaaSpocalypse. AI is not actually driving much revenue at all!
Boosters, I am begging of you — point to one thing TODAY, from TODAY’s models, that even remotely justifies burning nearly a trillion dollars and filling our internet full of slop and creating the moral distance from an action that might have blown up a school and empowering the theft of millions of people’s work and having to hear every fucking day about Sam Altman and Dario Amodei, two terrifyingly boring and annoying oafs with no culture and no whimsy in their wretched little hearts.
Even if you are impressed by what LLMs can do, remember that what you’re impressed by is the result of burning more money than anybody has ever burned on anything, including the Great Financial Crisis’ Troubled Asset Relief Plan (a little over $400 billion) and the COVID Paycheck Protection Program (somewhere between $800 billion and $900 billion). Anthropic and OpenAI have raised (assuming OpenAI gets all the money) over $200 billion in funding, on top nearly $700 billion in capex in 2026 alone across Google, Amazon, Meta, and Microsoft, on top of the $800 billion or so they’ve already spent. I haven’t even included the tens of billions spent by CoreWeave, or the $178.5 billion in US-based data center debt deals from 2025, or the hundreds of billions of venture dollars that went to AI companies worldwide.
Yet when you look even an inch below the surface, everything seems kind of shit.
Per my Hater’s Guide To The SaaSpocalypse:
Much is said of the rocketship growth of Cursor, which crossed $2 billion in annualized revenue in March, which seems good if you don’t realize that $2 billion annualized is $166 million a month, and that Cursor raised three billion fucking dollars in 2025 alone. Similarly, Harvey — which raised $200 million at an $11 billion valuation in February — can only cobble together $190 million in ARR, or $15.8 million a month, after hitting $100 million ARR ($8.3 million a month) in August 2025, raising $300 million in June 2025, and $300 million in February 2025.
Pretty much every AI startup is in SaaS and raises hundreds of millions of dollars so that it can make single or double-digit millions of dollars a month. This sounds sarcastic — petty even! — but it’s the truth, and nobody’s margins appear to be improving.
Lovable hit $400 million in annualized revenue a few weeks ago — better known as $33.3 million a month — and all it took was $15 million in February 2025, $200 million in July 2025 and $330 million in December 2025.
Every single AI startup without exception does the same thing: turn hundreds of millions of dollars into tens of millions of dollars, or a few billion dollars into a few hundred million dollars. None of them are improving their margins. None of them have a solution.
Every single problem I’ve discussed above about the costs of running Anthropic or OpenAI apply directly to every AI startup, except they have far less venture capital backing and are subject, as Cursor was back in June 2025, to whatever price increases Anthropic or OpenAI decide, such as adding “priority processing” that’s effectively mandatory to have consistent access to frontier models.
Absolutely none of these companies have a plan. The only reason anyone is still humouring them is that the media and venture capital continue to promote the idea that — without explaining how — they will magically find a way of becoming margin positive.
When? How? Those are problems for rubes who don’t know we’re living in the future! Let’s hope that venture capital can afford to fund them in perpetuity! They can’t, of course, because venture capital has had dogshit returns since 2018, and AI startups do not have much intellectual property, as most of them are just wrappers for frontier AI labs who also don’t have any path to profitability.
As I covered last week, the story is similar for public companies.
Adobe’s “AI-first” revenue ($375 million ARR) works out to about $60 million a quarter at most for a company that makes $6 billion a quarter. ServiceNow has “$600 million in annual contract value,” an extrapolation of a non-specific period’s revenue that does not actually mean $600 million for a company that makes over $10 billion a year. Salesforce’s Agentforce revenue is $800 million, or roughly $66 million a month for a company that makes over $11 billion a year. Shopify, the company that mandates you prove that AI can’t do a job before asking for resources, does not break out AI revenue. Workday, a company that makes about $2.5 billion a quarter in revenue, said it “generated over $100 million in new ACV from emerging AI products, [and that] overall ARR from these solutions was over $400 million.” $400 million ARR is $33 million a month.
To be clear, ARR is not a consistent figure, and churn happens all the time, especially for products like LLMs that have questionable outcomes and high prices. Four fucking years of this and we’re still talking about this stuff in riddles, mostly because it’s a terrible business.
Then there’s the infrastructure issue.
Is The Entire AI Infrastructure Story Bullshit?
One of the more-recent (and egregious) failures of journalism is the reporting of data center deals.
Before we go any further, one very important detail: when you read “active power,” that does not mean actual available compute capacity, which is called “IT load.” Per my premium data center model from a few months ago, you should take any “active power” and divide it by 1.3 to represent “PUE” — the standard for power usage effectiveness that calculates for everything that gets the power to the IT gear, and all the infrastructure that’s necessary to keep things running, like cooling systems.
Anywho, Bloomberg just reported that Meta had signed a “$27 billion” compute capacity deal with “$12 billion of capacity available in 2027” with AI compute company Nebius. Based on discussions with numerous experts in AI infrastructure, it works out to about $12.5 million per megawatt of compute, meaning that “$12 billion of dedicated capacity” would be around 960MW of IT Load.
And, of course, Nebius just raised $3.75bn in debt on the back of that compute deal.
This is on top of Microsoft’s $17.4 billion deal, and, of course, Meta’s $3 billion deal from last year.
One little problem: as of its February 12 2026 Letter to Shareholders, Nebius has around 170MW of active power.
How the fuck is it going to have that capacity ready, exactly?
For some context, CoreWeave — an AI compute company backed by (and backstopped by) NVIDIA with an entirely separate company building its capacity (Core Scientific) with backing from Blackstone and seemingly every major financier in the world — managed to go from 420MW of active power (NOT IT LOAD) in Q1 2025 to 850MW in active power in Q4 2025, with much of that already under construction in Q1 2025.
Nebius only started building its 300MW of New Jersey-based compute in March 2025, and based on its letter to shareholders, things aren’t going very well at all.
Then there’s Nscale, a company that raised $2 billion from NVIDIA, Lenovo and a bunch of other investors, and this week signed a “1.35GW deal” with Microsoft to fill a data center full of the latest generation of Vera Rubin GPUs.
In September 2025, NVIDIA CEO Jensen Huang said that the UK was going to be an “AI superpower” as he plunged hundreds of millions of dollars into Nscale as part of an “historic commitment to the UK AI sector” between NVIDIA, OpenAI, and Microsoft.
When The Guardian visited the supposed site of Nscale’s UK-based data center in February 2026 — which is meant to be built by the end of the year — it found “...a depot stacked with pylons and scrap metal under a corrugated roof, while flatbed lorries drove in and out stacked with poles.” As part of the investigation, The Guardian found that the supposed billions of dollars in data center commitments made by Nscale and CoreWeave were never checked by the government, and that no mechanism existed to audit them.
The response from both CoreWeave and Nscale was that these billions of dollars of investments would mostly be in NVIDIA GPUs, which is where we get to the “why” of these massive compute contracts.
The Data Center Debt Financial Crisis Has Now Pulled In Insurance And Pension Funds, Using The Markets’ AI Psychosis To Make Them Ignore Junk Ratings
You see, when Nebius, or Nscale, or CoreWeave signs a giant deal that it doesn’t have the capacity to provide, it does so specifically to raise debt on the contract to buy NVIDIA GPUs.
See the below diagram from CoreWeave’s Q1 2025 earnings presentation:
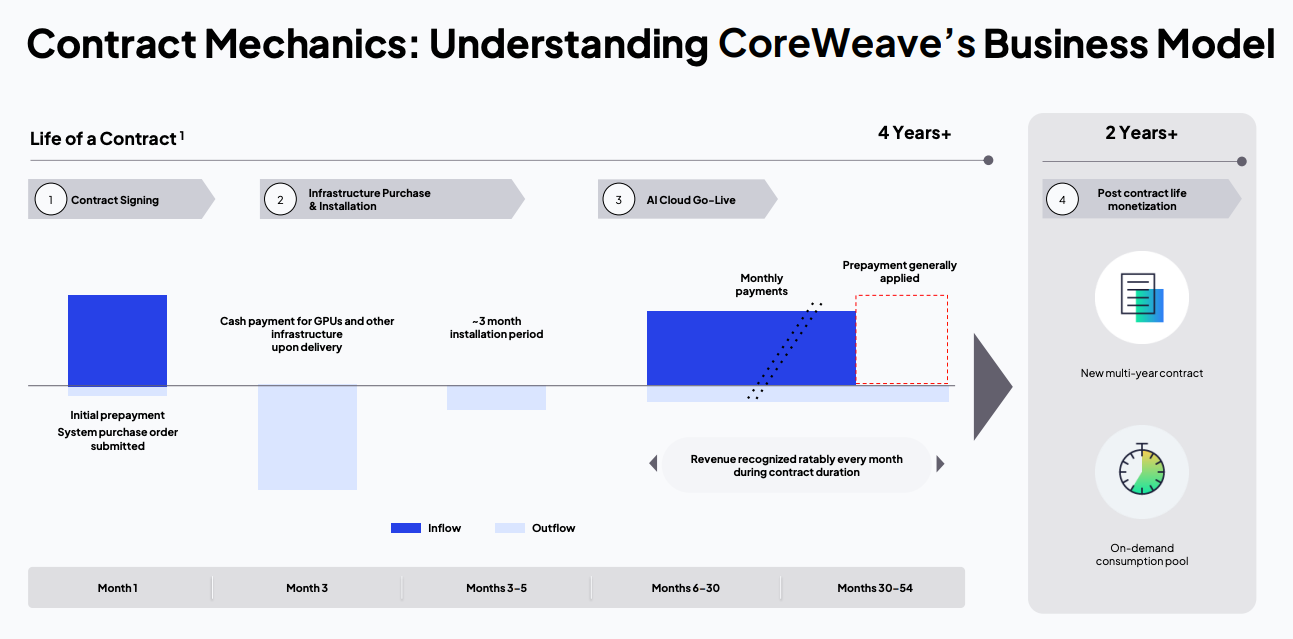
If people were actually paying attention, they’d see the immediate problem: a data center takes an incredible amount of time to build, and takes longer depending on the amount of capacity necessary.
It’s a deeply cynical con. Hyperscalers like Microsoft and Meta are paying for these contracts because they don’t reflect as assets on the balance sheet, all while moving the risk onto the AI compute company — and if the AI company misses a deadline, the hyperscaler can walk away.
For example, Nebius’ deal with Microsoft from last year has a clause that says that “...fails to meet agreed delivery dates for a GPU Service and the Company cannot provide alternative capacity, Microsoft has the right to terminate that GPU Service.”
Based on discussions with people with direct knowledge of its infrastructure, Microsoft has already set up Nebius to fail, with the expectation that it would have over 50MW of IT load specifically made up of NVIDIA’s GB200 and GB300 GPUs available by the end of April, with at least another 150MW of IT load (or more) by the end of the year for a company that only has about 130MW of IT Load in its entire global infrastructure, most of which isn’t in Vineland, New Jersey.
Hyperscalers are helping no-name companies with little or no history or experience in building data centers borrow billions of dollars in debt which is increasingly funded by people’s retirements and insurance funds lured in by the idea of “consistent yields” from companies that cannot afford to do business without convincing everybody to believe the illogical.
Data centers take forever to build. The “1.2GW” (so 880MW of IT load) Stargate Abilene’s first two buildings were meant to be fully energized by the middle of 2025. Only the first two-buildings’ worth of 96,000 GPUs were “delivered” by the middle of December 2025, and while the entire project was meant to be energized by mid-2026, it appears that only two buildings are actually ready to go.
Every time you report on these deals should include a timeline. In the end, I bet Stargate Abilene never gets built, but if it does, I’d be shocked if it’s done before the middle of 2027, which would mean it takes about 3 years per Gigawatt of power, or about a year per 293MW of IT load.
I have read absolutely zero fucking stories about data center development that take this into account.
The flippancy with which the media reports on these data centers — both in the structure of the deals and the realities of the construction (I go into detail about this in a premium from late last year, but making data centers is hard) — is allowing con artists to get rich and creating the conditions for yet another great financial crisis.
Pension funds and state investment boards are reading about these deals, seeing “Microsoft,” and assuming that everything will be fine, per my Hater’s Guide To Private Equity:
Insurance (and, for that matter, retirement) companies need those regular payouts to actually do business. They crave yield — regular payments for their investments — and private credit bonds (as in the bonds used to raise the money for private credit in some cases) tend to pay better than others, and nobody bothers to think about why that might be, such as “the investments are riskier, because they’re often issued by “trustworthy” companies or in assets that people believe are going to be a big deal.
All that the pension fund sees is an article on CNBC or Bloomberg and the name of a company like Microsoft or Meta. In turn, they (or the private credit firm managing their money) buy bonds or fund these debt deals because they see them as stable, straightforward, reliable investment yields, because the media and private credit firms are selling them as such.
In reality, data center debt deals are incredibly dangerous, as each one is effectively a bet on both the existence of AI demand (so that the debt can be repaid with revenue) and the existence of the company in question as an ongoing concern. Nscale, Nebius and CoreWeave are only a few years old, and the concept of a 1GW data center is not much older.
During the great financial crisis, massive amounts — billions and billions of dollars’ worth — of pension and insurance funds went into Collateralized Debt Obligations (CDOs) that were rated as AAA despite being a rat king of low-grade (and in many cases delinquent) debt.
This time around, data center debt deals are often given junk ratings — such as the B+ rating given to one of CoreWeave’s 2025 debt deals — which might make you think that there’s nothing to worry about, and that investors would naturally steer clear of these investments.
The problem is that the markets have AI psychosis, and thus believe anything to do with data centers is a natural winner. Blackstone funded part of its $38 billion investment in Oracle’s data centers — you know, the ones explicitly built for OpenAI, which cannot afford to pay for the compute — using its insurance funds. Per The Information:
“These are long-term contracts with committed revenue streams, so they should operate very similarly to the bonds that some of these hyperscalers are issuing directly,” said Julie Brewer, head of finance at EdgeCore Digital Infrastructure, a Denver-based data center developer.
This is the standard line from anybody in finance about data centers, and is based on little more than wish-casting and fantasy. These are brand new kinds of debt for some of the largest infrastructure projects in history, and as I’ve discussed repeatedly, outside of hyperscalers moving compute off of their balance sheets, there’s only a billion dollars of compute demand.
77% of CoreWeave’s 2025 revenue — and keep in mind that CoreWeave is the largest independent AI compute provider — was from Microsoft and NVIDIA, the latter of which plans to spend $26 billion in the next five years on renting back its GPUs…which suggests that little organic demand exists.
2026 or 2027’s great financial crisis will replace “homes” with “data centers,” and I worry it’ll be calamitous for the pensions and insurance funds that have tied their futures to AI.
—-
Even putting aside my own personal feelings about LLMs…I’m just not sure why we’re doing this anymore.
Okay, okay, I know why we’re doing it — the software industry is out of hypergrowth ideas and has been in a years-long decline since 2018, though it briefly had a burst of excitement in 2021 when money was cheap and everybody was insane after the lockdowns ended.
Nevertheless, AI has become one of the largest cons in history, bought and sold based on stuff it can’t do (but might do, one day, at a non-specific time), constantly ignoring the blatant swindles and acidic economics that are only made possible with regulators and the media and the markets piloted by people that don’t know or want to know what’s actually happening.
If you are an AI fan, I need to genuinely ask you to consider whether what you’re impressed by is what the LLMs can do today rather than what they might be able to do tomorrow. If you’re excited based on the potential, you’re not excited about technology, you’re excited about marketing.
And I get it. The tech industry hasn’t had anything really exciting in a while. It’s easy to get swept away by hype, especially when everybody is being swept away in exactly the same way. It’s hard to push back when Microsoft, Google, Meta and Amazon are all participating in a financial death cult, and their revenues keep growing — having to understand anything more than the headlines is tough and you’ve got all this shit to do and it’s so much easier to just nod and agree with everybody else.
But know that this is an industry that sells itself on fear and lies. Know that LLMs cannot do many of the things that people talk about — they do not blackmail people, no GPT-4 did not trick a taskrabbit, and every single time an AI CEO says AI “will” do something you should spit in their fucking face for making shit up not print it without a second’s thought.
It’s time to get specific. What will AI do, and when will it do it? What will the actual software be? How will it work? How much will it cost? How will it make money? How will it become profitable?
Because right now we’re being sold a lie and I’m sick of it, almost as sick as I am of seeing critics framed as outlier factions spreading conspiracy theories. I’ve proven my point again and again and again. Where is the same effort from the AI boosters? All I see is the occasional desperate attempt to claim that LLMs doing what they’ve always done is somehow remarkable?
Oh wow, so you can code a clone of an open source software project, all set up with an LLM that may or may not get the code right. Oh, someone was able to vibe code something that may or may not work and looks exactly the same as every other vibe code project. Congratulations on making a website that’s purple for some reason — you’re puking out a facsimile of an era of websites defined by the colour scheme chosen by Tailwind CSS.
I also want to be clear that I am extremely nervous about how many people appear to be fine with not reading code. I am currently (very slowly) learning Python, and every new thing I learn reinforces my overwhelming anxiety that there is a lot of software being written today by people who don’t read the output from LLMs and, in some cases, may not have understood it if they did. While I’m not saying all or even many software engineers might do this, I am alarmed by the idea that it’s becoming more commonplace — and even more alarmed that the reaction appears to be “ah it’s fine who gives a shit, it works.”
Guess what! It doesn’t always work. Amazon Web Services had multiple recent outages caused by use of its Kiro AI coding tool, and while it insists that AI isn’t to blame, it also convened an internal meeting to discuss this specific issue, and The Financial Times reported that Amazon now requires junior and mid-level engineers to get sign off on AI-assisted changes to code. However you may feel about Amazon as a service, its engineers are likely indicative of corporate engineering on some level, which is making me wonder if we’re not going to have some real problems in software development in the next few years as a result.
What does the software industry look like if nobody is actually reading their code? How many software engineers are comfortable doing this? I’m sure somebody will read this and get terribly offended, but to be clear, I’m not accusing you of copy-pasting code you can’t understand and being happy if it works unless that’s exactly what you’re doing.
To be explicit, allowing LLM to write all of your code means that you are no longer developing code, nor are you learning how to develop code, nor are you going to become a better software engineer as a result.
This isn’t even an insult or hyperbole. If you are just a person looking at code, you are only as good as the code the model makes, and as Mo Bitar recently discussed, these models are built to galvanize you, glaze you, and tell you that you’re remarkable as you barely glance at globs of overwritten code that, even if it functions, eventually grows to a whole built with no intention or purpose other than what the model generated from your prompt.
I’m sure there are software engineers using these models ethically, who read all the code, who have complete industry over it and use it like a glorified autocomplete. I’m also sure that there are some that are just asking it to do stuff, glancing at the code and shipping it. It’s impossible to measure how many of each camp there are, but hearing Spotify’s CEO say that its top developers are basically not writing code anymore makes me deeply worried, because this shit isn’t replacing software engineering at all — it’s mindlessly removing friction and putting the burden of “good” or “right” on a user that it’s intentionally gassing up.
Ultimately, this entire era is a test of a person’s ability to understand and appreciate friction.
Friction can be a very good thing. When I don’t understand something, I make an effort to do so, and the moment it clicks is magical. In the last three years I’ve had to teach myself a great deal about finance, accountancy, and the greater technology industry, and there have been so many moments where I’ve walked away from the page frustrated, stewed in self-doubt that I’d never understand something.
I also have the luxury of time, and sadly, many software engineers face increasingly-deranged deadlines set by bosses that don’t understand a single fucking thing, let alone what LLMs are capable of or what responsible software engineering is. The push from above to use these models because they can “write code faster than a human” is a disastrous conflation of “fast” and “good,” all because of flimsy myths peddled by venture capitalists and the media about “LLMs being able to write all code.”
The problem is that LLMs can write all code, but that doesn’t mean the code is good, or that somebody can read the code and understand its intention, or that having a lot of code is a good thing both in the present and in the future of any company built using generative code.
And in the end, where are the signs that this is working? Where are the vibe coded software products destabilizing incumbents? Where are the actual software engineers being replaced — not that I want this to happen, to be clear — by LLMs, outside of AI-washing stories that have got so egregious that even Sam Altman called it out? Where is the revenue? Where are the returns? Where are the outcomes?
Why are we still doing this?
