
Soundtrack: Queens of the Stone Age - First It Giveth
Before we go any further: This is, for the third time this year, the longest newsletter I've ever written, weighing in somewhere around 18,500 words. I've written it specifically to be read at your leisure — dip in and out where you'd like — but also in one go.
This is my comprehensive case that yes, we’re in a bubble, one that will inevitably (and violently) collapse in the near future.
I'll also be cutting this into a four-part episode starting tomorrow on my podcast Better Offline.
I deeply appreciate your time. If you like this newsletter, please think about subscribing to the premium, which I write weekly.
Thanks for reading.
"No of course there isn't enough capital for all of this. Having said that, there is enough capital to do this for at least a little while longer."
Analyst Gil Luria of D.A. Davidson, on being asked if there was enough available capital to build OpenAI’s promised 17 Gigawatts of data centers.
Alright, let’s do this one last time.
In 2022, a (kind-of) company called OpenAI surprised the world with a website called ChatGPT that could generate text that sort-of sounded like a person using a technology called Large Language Models (LLMs), which can also be used to generate images, video and computer code.
Large Language Models require entire clusters of servers connected with high-speed networking, all containing this thing called a GPU — graphics processing units. These are different to the GPUs in your Xbox, or laptop, or gaming PC. They cost much, much more, and they’re good at doing the processes of inference (the creation of the output of any LLM) and training (feeding masses of training data to models, or feeding them information about what a good output might look like, so they can later identify a thing or replicate it).
These models showed some immediate promise in their ability to articulate concepts or generate video, visuals, audio, text and code. They also immediately had one glaring, obvious problem: because they’re probabilistic, these models can’t actually be relied upon to do the same thing every single time.
So, if you generated a picture of a person that you wanted to, for example, use in a story book, every time you created a new page, using the same prompt to describe the protagonist, that person would look different — and that difference could be minor (something that a reader should shrug off), or it could make that character look like a completely different person.
Moreover, the probabilistic nature of generative AI meant that whenever you asked it a question, it would guess as to the answer, not because it knew the answer, but rather because it was guessing on the right word to add in a sentence based on previous training data. As a result, these models would frequently make mistakes — something which we later referred to as “hallucinations.”
And that’s not even mentioning the cost of training these models, the cost of running them, the vast amounts of computational power they required, the fact that the legality of using material scraped from books and the web without the owner’s permission was (and remains) legally dubious, or the fact that nobody seemed to know how to use these models to actually create profitable businesses.
These problems were overshadowed by something flashy, and new, and something that investors — and the tech media — believed would eventually automate the single thing that’s proven most resistant to automation: namely, knowledge work and the creative economy.
This newness and hype and these expectations sent the market into a frenzy, with every hyperscaler immediately creating the most aggressive market for one supplier I’ve ever seen. NVIDIA has sold over $200 billion of GPUs since the beginning of 2023, becoming the largest company on the stock market and trading at over $170 as of writing this sentence only a few years after being worth $19.52 a share.
Sidenote: those figures reflect the fact that Nvidia’s stock split 10-to-1 in 2024 — or, said plainly, if you held one share before the split, you’d hold ten shares afterwards, changing the unit price of the company’s equity (making it cheaper to buy a share, and thus, more accessible to retail investors) without changing the absolute value of the company.
This bit isn’t necessarily important to what I’ve written, but given the subject of this newsletter, I think it’s important to lean towards being as explicit as possible about the numbers I share.
While I’ve talked about some of the propelling factors behind the AI wave — automation and novelty — that’s not a complete picture. A huge reason why everybody decided to “do AI” was because the software industry’s growth was slowing, with SaaS (Software As A Service) company valuations stalling or dropping, resulting in the terrifying prospect of companies having to “under promise and over deliver” and “be efficient.”
Things that normal companies — those whose valuations aren’t contingent on ever-increasing, ever-constant growth — don’t have to worry about, because they’re normal companies.
Suddenly, there was the promise of a new technology — Large Language Models — that were getting exponentially more powerful, which was mostly a lie but hard to disprove because “powerful” can mean basically anything, and the definition of “powerful” depended entirely on whoever you asked at any given time, and what that person’s motivations were.
The media also immediately started tripping on its own feet, mistakenly claiming OpenAI’s GPT-4 model tricked a Taskrabbit into solving a CAPTCHA (it didn’t — this never happened), or saying that “people who don’t know how to code already [used] bots to produce full-fledged games,” and if you’re wondering what “full-fledged” means, it means “pong” and a cobbled-together rolling demo of SkyRoads, a game from 1993.
The media (and investors) helped peddle the narrative that AI was always getting better, could do basically anything, and that any problems you saw today would be inevitably solved in a few short months, or years, or, well, at some point I guess.
LLMs were touted as a digital panacea, and the companies building them offered traditional software companies the chance to plug these models into their software using an API, thus allowing them to ride the same generative AI wave that every other company was riding.
The model companies similarly started going after individual and business customers, offering software and subscriptions that promised the world, though this mostly boiled down to chatbots that could generate stuff, and then doubled down with the promise of “agents” — a marketing term that’s meant to make you think “autonomous digital worker” but really means “broken digital product.”
Throughout this era, investors and the media spoke with a sense of inevitability that they never really backed up with data. It was an era based on confidently-asserted “vibes.” Everything was always getting better and more powerful, even though there was never much proof that this was truly disruptive technology, other than in its ability to disrupt apps you were using with AI — making them worse by, for example, suggesting questions on every Facebook post that you could ask Meta AI, but which Meta AI couldn’t answer.
“AI” was omnipresent, and it eventually grew to mean everything and nothing. OpenAI would see its every move lorded over like a gifted child, its CEO Sam Altman called the “Oppenheimer of Our Age,” even if it wasn’t really obvious why everyone was impressed. GPT-4 felt like something a bit different, but was it actually meaningful?
The thing is, Artificial Intelligence is built and sold on not just faith, but a series of myths that the AI boosters expect us to believe with the same certainty that we treat things like gravity, or the boiling point of water.
Can large language models actually replace coders? Not really, no, and I’ll get into why later in the piece.
Can Sora — OpenAI’s video creation tool — replace actors or animators? No, not at all, but it still fills the air full of tension because you can immediately see who is pre-registered to replace everyone that works for them.
AI is apparently replacing workers, but nobody appears to be able to prove it! But every few weeks a story runs where everybody tries to pretend that AI is replacing workers with some poorly-sourced and incomprehensible study, never actually saying “someone’s job got replaced by AI” because it isn’t happening at scale, and because if you provide real-world examples, people can actually check.
To be clear, some people have lost jobs to AI, just not the white collar workers, software engineers, or really any of the career paths that the mainstream media and AI investors would have you believe.
Brian Merchant has done excellent work covering how LLMs have devoured the work of translators, using cheap, “almost good” automation to lower already-stagnant wages in a field that was already hurting before the advent of generative AI, with some having to abandon the field, and others pushed into bankruptcy. I’ve heard the same for art directors, SEO experts, and copy editors, and Christopher Mims of the Wall Street Journal covered these last year.
These are all fields with something in common: shitty bosses with little regard for their customers who have been eagerly waiting for the opportunity to slash contract labor. To quote Merchant, “the drumbeat, marketing, and pop culture of ‘powerful AI’ encourages and permits management to replace or degrade jobs they might not otherwise have.”
Across the board, the people being “replaced” by AI are the victims of lazy, incompetent cost-cutters who don’t care if they ship poorly-translated text. To quote Merchant again, “[AI hype] has created the cover necessary to justify slashing rates and accepting “good enough” automation output for video games and media products.”
Yet the jobs crisis facing translators speaks to the larger flaws of the Large Language Model era, and why other careers aren’t seeing this kind of disruption.
Generative AI creates outputs, and by extension defines all labor as some kind of output created from a request. In the case of translation, it’s possible for a company to get by with a shitty version, because many customers see translation as “what do these words say,” even though (as one worker told Merchant) translation is about conveying meaning. Nevertheless, “translation” work had already started to condense to a world where humans would at times clean up machine-generated text, and the same worker warned that the same might come for other industries.
Yet the problem is that translation is a heavily output-driven industry, one where (idiot) bosses can say “oh yeah that’s fine” because they ran an output back through Google Translate and it seemed fine in their native tongue. The problems of a poor translation are obvious, but the customers of translation are, it seems, often capable of getting by with a shitty product.
The problem is that most jobs are not output-driven at all, and what we’re buying from a human being is a person’s ability to think.
Every CEO talking about AI replacing workers is an example of the real problem: that most companies are run by people who don’t understand or experience the problems they’re solving, don’t do any real work, don’t face any real problems, and thus can never be trusted to solve them. The Era of the Business Idiot is the result of letting management consultants and neoliberal “free market” sociopaths take over everything, leaving us with companies run by people who don’t know how the companies make money, just that they must always make more.
When you’re a big, stupid asshole, every job that you see is condensed to its outputs, and not the stuff that leads up to the output, or the small nuances and conscious decisions that make an output good as opposed to simply acceptable, or even bad.
What does a software engineer do? They write code! What does a writer do? They write words! What does a hairdresser do? They cut hair!
Yet that’s not actually the case.
As I’ll get into later, a software engineer does far more than just code, and when they write code they’re not just saying “what would solve this problem?” with a big smile on their face — they’re taking into account their years of experience, what code does, what code could do, all the things that might break as a result, and all of the things that you can’t really tell from just looking at code, like whether there’s a reason things are made in a particular way.
A good coder doesn’t just hammer at the keyboard with the aim of doing a particular task. They factor in questions like: How does this functionality fit into the code that’s already here? Or, if someone has to update this code in the future, how do I make it easy for them to understand what I’ve written and to make changes without breaking a bunch of other stuff?
A writer doesn’t just “write words.” They jostle ideas and ideals and emotions and thoughts and facts and feelings into a condensed piece of text, explaining both what’s happening and why it’s happening from their perspective, finding nuanced ways to convey large topics, none of which is the result of a single (or many) prompts but the ever-shifting sand of a writer’s brain.
Good writing is a fight between a bunch of different factors: structure, style, intent, audience, and prioritizing the things that you (or your client) care about in the text. It’s often emotive — or at the very least, driven or inspired by a given emotion — which is something that an AI simply can’t replicate in a way that’s authentic and believable.
And a hairdresser doesn’t just cut hair, but cuts your hair, which may be wiry, dry, oily, long, short, healthy, unhealthy, on a scalp with particular issues, at a time of year when perhaps you want to change length, at a time that fits you, in “the way you like” which may be impossible to actually write down but they get it just right. And they make conversation, making you feel at ease while they snip and clip away at your tresses, with you having to trust that they’ll get it right.
This is the true nature of labor that executives fail to comprehend at scale: that the things we do are not units of work, but extrapolations of experience, emotion, and context that cannot be condensed in written meaning. Business Idiots see our labor as the result of a smart manager saying “do this,” rather than human ingenuity interpreting both a request and the shit the manager didn’t say.
What does a CEO do? Uhhh, um, well, a Harvard study says they spend 25% of their time on “people and relationships,” 25% on “functional and business unit reviews,” 16% on “organization and culture,” and 21% on “strategy,” with a few percent here and there for things like “professional development.”
That’s who runs the vast majority of companies: people that describe their work predominantly as “looking at stuff,” “talking to people” and “thinking about what we do next.” The most highly-paid jobs in the world are impossible to describe, their labor described in a mish-mash of LinkedInspiraton, yet everybody else’s labor is an output that can be automated.
As a result, Large Language Models seem like magic. When you see everything as an outcome — an outcome you may or may not understand, and definitely don’t understand the process behind, let alone care about — you kind of already see your workers as LLMs.
You create a stratification of the workforce that goes beyond the normal organizational chart, with senior executives — those closer to the class level of CEO — acting as those who have risen above the doldrums of doing things to the level of “decisionmaking,” a fuzzy term that can mean everything from “making nuanced decisions with input from multiple different subject-matter experts” to, as ServiceNow Bill McDermott did in 2022, “[make] it clear to everybody [in a boardroom of other executives], everything you do: AI, AI, AI, AI, AI.”
The same extends to some members of the business and tech media that have, for the most part, gotten by without having to think too hard about the actual things the companies are saying.
I realize this sounds a little mean, and I must be clear it doesn’t mean that these people know nothing, just that it’s been possible to scoot through the world without thinking too hard about whether or not something is true. When Salesforce said back in 2024 that its “Einstein Trust Layer” and AI would be “transformational for jobs,” the media dutifully wrote it down and published it without a second thought. It fully trusted Marc Benioff when he said that Agentforce agents would replace human workers, and then again when he said that AI agents are doing “30% to 50% of all the work in Salesforce itself,” even though that’s an unproven and nakedly ridiculous statement.
Salesforce’s CFO said earlier this year that AI wouldn’t boost sales growth in 2025. One would think this would change how they’re covered, or how seriously one takes Marc Benioff.
It hasn’t, because nobody is paying attention. In fact, nobody seems to be doing their job.
This is how the core myths of generative AI were built: by executives saying stuff and the media publishing it without thinking too hard.
AI is replacing workers! AI is writing entire computer programs! AI is getting exponentially more-powerful! What does “powerful” mean? That the models are getting better on benchmarks that are rigged in their favor, but because nobody fucking explains it, regular people are regularly told that AI is “powerful.”
The only thing “powerful” about generative AI is its mythology. The world’s executives, entirely disconnected from labor and actual production, are doing the only thing they know how to — spend a bunch of money and say vague stuff about “AI being the future.” There are people — journalists, investors, and analysts — that have built entire careers on filling in the gaps for the powerful as they splurge billions of dollars and repeat with increasing desperation that “the future is here” as absolutely nothing happens.
You’ve likely seen a few ridiculous headlines recently. One of the most recent, and most absurd, is that that OpenAI will pay Oracle $300 billion over four years, closely followed with the claim that NVIDIA will “invest” “$100 billion” in OpenAI to build 10GW of AI data centers, though the deal is structured in a way that means that OpenAI is paid “progressively as each gigawatt is deployed,” and OpenAI will be leasing the chips (rather than buying them outright). I must be clear that these deals are intentionally made to continue the myth of generative AI, to pump NVIDIA, and to make sure OpenAI insiders can sell $10.3 billion of shares.
OpenAI cannot afford the $300 billion, NVIDIA hasn’t sent OpenAI a cent and won’t do so if it can’t build the data centers, which OpenAI most assuredly can’t afford to do.
NVIDIA needs this myth to continue, because in truth, all of these data centers are being built for demand that doesn’t exist, or that — if it exists — doesn’t necessarily translate into business customers paying huge amounts for access to OpenAI’s generative AI services.
NVIDIA, OpenAI, CoreWeave and other AI-related companies hope that by announcing theoretical billions of dollars (or hundreds of billions of dollars) of these strange, vague and impossible-seeming deals, they can keep pretending that demand is there, because why else would they build all of these data centers, right?
That, and the entire stock market rests on NVIDIA’s back. It accounts for 7% to 8% of the value of the S&P 500, and Jensen Huang needs to keep selling GPUs. I intend to explain later on how all of this works, and how brittle it really is.
The intention of these deals is simple: to make you think “this much money can’t be wrong.”
It can. These people need you to believe this is inevitable, but they are being proven wrong, again and again, and today I’m going to continue doing so.
Underpinning these stories about huge amounts of money and endless opportunity lies a dark secret — that none of this is working, and all of this money has been invested in a technology that doesn’t make much revenue and loves to burn millions or billions or hundreds of billions of dollars.
Over half a trillion dollars has gone into an entire industry without a single profitable company developing models or products built on top of models. By my estimates, there is around $44 billion of revenue in generative AI this year (when you add in Anthropic and OpenAI’s revenues to the pot, along with the other stragglers) and most of that number has been gathered through reporting from outlets like The Information, because none of these companies share their revenues, all of them lose shit tons of money, and their actual revenues are really, really small.
Only one member of the Magnificent Seven (outside of NVIDIA) has ever disclosed its AI revenue — Microsoft, which stopped reporting in January 2025, when it reported “$13 billion in annualized revenue,” so around $1.083 billion a month.
Microsoft is a sales MACHINE. It is built specifically to create or exploit software markets, suffocating competitors by using its scale to drive down prices, and to leverage the ecosystem that it’s created over the past few decades. $1 billion a month in revenue is chump change for an organization that makes over $27 billion a quarter in PROFITS.
Don’t worry Satya, I’ll come back to you later.
“But Ed, the early days!” Worry not — I’ve got that covered.
This is nothing like any other era of tech. There has never been this kind of cash-rush, even in the fiber boom. Over a decade, Amazon spent about one-tenth of the capex that the Magnificent Seven spent in two years on generative AI building AWS — something that now powers a vast chunk of the web, and has long been Amazon’s most profitable business unit.
Generative AI is nothing like Uber, with OpenAI and Anthropic’s true costs coming in at about $159 billion in the past two years, approaching five times Uber’s $30 billion all-time burn. And that’s before the bullshit with NVIDIA and Oracle.
Microsoft last reported AI revenue in January. It’s October this week. Why did it stop reporting this number, you think? Is it because the numbers are so good it couldn’t possibly let people know?
As a general rule, publicly traded companies — especially those where the leadership are compensated primarily in equity — tend to brag about their successes, in part because said bragging boosts the value of the thing that the leadership gets paid in. There’s no benefit to being shy. Oracle literally made a regulatory filing to boast it had a $30 billion customer, which turned out to be OpenAI, who eventually agreed (publicly) to spend $300 billion in compute over five years.
Which is to say that Microsoft clearly doesn’t have any good news to share, and as I’ll reveal later, they can’t even get 3% of their 440 million Microsoft 365 subscribers to pay for Microsoft 365 Copilot.
If Microsoft can’t sell this shit, nobody can.
Anyway, I’m nearly done, sorry, you see, I’m writing this whole thing as if you’re brand new and walking up to this relatively unprepared, so I need to introduce another company.
In 2020, a splinter group jumped off of OpenAI, funded by Amazon and Google to do much the same thing as OpenAI but pretend to be nicer about it until they have to raise from the Middle East. Anthropic has always been better at coding for some reason, and people really like its Claude models.
Both OpenAI and Anthropic have become the only two companies in generative AI to make any real progress, either in terms of recognition or in sheer commercial terms, accounting for the majority of the revenue in the AI industry.
In a very real sense, the AI industry’s revenue is OpenAI and Anthropic. In the year where Microsoft recorded $13bn in AI revenues, $10 billion came from OpenAI’s spending on Microsoft Azure. Anthropic burned $5.3 billion last year — with the vast majority of that going towards compute. Outside of these two companies, there’s barely enough revenue to justify a single data center.
Where we sit today is a time of immense tension. Mark Zuckerberg says we’re in a bubble, Sam Altman says we’re in a bubble, Alibaba Chairman and billionaire Joe Tsai says we’re in a bubble, Apollo says we’re in a bubble, nobody is making money and nobody knows why they’re actually doing this anymore, just that they must do it immediately.
And they have yet to make the case that generative AI warranted any of these expenditures.
That was undoubtedly the longest introduction to a newsletter I’ve ever written, and the reason why I took my time was because this post demands a level of foreshadowing and exposition, and because I want to make it make sense to anyone who reads it — whether they’ve read my newsletter for years, or whether they’re only just now investigating their suspicions that generative AI may not be all it’s cracked up to be.
Today I will make the case that generative AI’s fundamental growth story is flawed, and explain why we’re in the midst of an egregious bubble.
This industry is sold by keeping things vague, and knowing that most people don’t dig much deeper than a headline, a problem I simply do not have.
This industry is effectively in service of two companies — OpenAI and NVIDIA — who pump headlines out through endless contracts between them and subsidiaries or investments to give the illusion of activity.
OpenAI is now, at this point, on the hook for over a trillion dollars, an egregious sum for a company that already forecast billions in losses, with no clear explanation as to how it’ll afford any of this beyond “we need more money” and the vague hope that there’s another Softbank or Microsoft waiting in the wings to swoop in and save the day.
I’m going to walk you through where I see this industry today, and why I see no future for it beyond a fiery apocalypse.
While everybody (reasonably!) harps on about hallucinations — which, to remind you, is when a model authoritatively states something that isn’t true — but the truth is far more complex, and far worse than it seems.
You cannot rely on a large language model to do what you want. Even the most highly-tuned models on the most expensive and intricate platform can’t actually be relied upon to do exactly what you want.
A “hallucination” isn’t just when these models say something that isn’t true. It’s when they decide to do something wrong because it seems the most likely thing to do, or when a coding model decides to go on a wild goose chase, failing the user and burning a ton of money in the process.
The advent of “reasoning” models — those engineered to ‘think’ through problems in a way reminiscent of a human — and the expansion of what people are (trying) to use LLMs for demands that the definition of an AI hallucination be widened, not merely referring to factual errors, but fundamental errors in understanding the user’s request or intent, or what constitutes a task, in part because these models cannot think and do not know anything.
However successful a model might be in generating something good *once*, it will also often generate something bad, or it’ll generate the right thing but in an inefficient and over-verbose fashion. You do not know what you’re going to get each time, and hallucinations multiply with the complexity of the thing you’re asking for, or whether a task contains multiple steps (which is a fatal blow to the idea of “agents.”
You can add as many levels of intrigue and “reasoning” as you want, but Large Language Models cannot be trusted to do something correctly, or even consistently, every time. Model companies have successfully convinced everybody that the issue is that users are prompting the models wrong, and that people need to be “trained to use AI,” but what they’re doing is training people to explain away the inconsistencies of Large Language Models, and to assume individual responsibility for what is an innate flaw in how large language models work.
Large Language Models are also uniquely expensive. Many mistakenly try and claim this is like the dot com boom or Uber, but the basic unit economics of generative AI are insane. Providers must purchase tens or hundreds of thousands of GPUs each costing $50,000 a piece, and hundreds of millions or billions of dollars of infrastructure for large clusters. And that’s without mentioning things like staffing, construction, power, or water.
Then you turn them on and start losing money. Despite hundreds of billions of GPUs sold, nobody seems to make any money, other than NVIDIA, the company that makes them, and resellers like Dell and Supermicro who buy the GPUs, put them in servers, and sell them to other people.
This arrangement works out great for Jensen Huang, and terribly for everybody else.
I am going to explain the insanity of the situation we find ourselves in, and why I continue to do this work undeterred. The bubble has entered its most pornographic, aggressive and destructive stage, where the more obvious it becomes that they’re cooked, the more ridiculous the generative AI industry will act — a dark juxtaposition against every new study that says “generative AI does not work” or new story about ChatGPT’s uncanny ability to activate mental illness in people.
The Markets Have Become Dependent On NVIDIA, and NVIDIA Is Taking Extraordinary, Dangerous Measures To Sustain Growth, Investing In Companies Specifically To Raise Debt To Buy Their Own GPUs
So, let’s start simple: NVIDIA is a hardware company that sells GPUs, including the consumer GPUs that you’d see in a modern gaming PC, but when you read someone say “GPU” within the context of AI, they mean enterprise-focused GPUs like the A100, H100, H200, and more modern GPUs like the Blackwell-series B200 and GB200 (which combines two GPUs with an NVIDIA CPU).
These GPUs cost anywhere from $30,000 to $50,000 (or as high as $70,000 for the newer Blackwell GPUs), and require tens of thousands of dollars more of infrastructure — networking to “cluster” server racks of GPUs together to provide compute, and massive cooling systems to deal with the massive amounts of heat they produce, as well as the servers themselves that they run on, which typically use top-of-the-line data center CPUs, and contain vast quantities of high-speed memory and storage. While the GPU itself is likely the most expensive single item within an AI server, the other costs — and I’m not even factoring in the actual physical building that the server lives in, or the water or electricity that it uses — add up.
I’ve mentioned NVIDIA because it has a virtual monopoly in this space. Generative AI effectively requires NVIDIA GPUs, in part because it’s the only company really making the kinds of high-powered cards that generative AI demands, and because NVIDIA created something called CUDA — a collection of software tools that lets programmers write software that runs on GPUs, which were traditionally used primarily for rendering graphics in games.
While there are open-source alternatives, as well as alternatives from Intel (with its ARC GPUs) and AMD (Nvidia’s main rival in the consumer space), these aren’t nearly as mature or feature-rich.
Due to the complexities of AI models, one cannot just stand up a few of these things either — you need clusters of thousands, tens of thousands, or hundreds of thousands of them for it to be worthwhile, making any investment in GPUs in the hundreds of millions or billions of dollars, especially considering they require completely different data center architecture to make them run.
A common request — like asking a generative AI model to parse through thousands of lines of code and make a change or an addition — may use multiple of these $50,000 GPUs at the same time, and so if you aspire to serve thousands, or millions of concurrent users, you need to spend big. Really big.
It’s these factors — the vendor lock-in, the ecosystem, and the fact that generative AI only works when you’re buying GPUs at scale — that underpin the rise of Nvidia. But beyond the economic and technical factors, there are human ones, too.
To understand the AI bubble is to understand why CEOs do the things they do. Because an executive’s job is so vague, they can telegraph the value of their “labor” by spending money on initiatives and making partnerships.
AI gave hyperscalers the excuse to spend hundreds of billions of dollars on data centers and buy a bunch of GPUs to go in them, because that, to the markets, looks like they’re doing something. By virtue of spending a lot of money in a frighteningly short amount of time, Satya Nadella received multiple glossy profiles, all without having to prove that AI can really do anything, be it a job or make Microsoft money.
Nevertheless, AI allowed CEOs to look busy, and once the markets and journalists had agreed on the consensus opinion that “AI would be big,” all that these executives had to do was buy GPUs and “do AI.”
We are in the midst of one of the darkest forms of software in history, described by many as an unwanted guest invading their products, their social media feeds, their bosses’ empty minds, and resting in the hands of monsters. Every story of its success feels bereft of any real triumph, with every literal description of its abilities involving multiple caveats about the mistakes it makes or the incredible costs of running it.
Generative AI exists for two reasons: to cost money, and to make executives look busy. It was meant to be the new enterprise software and the new iPhone and the new Netflix all at once, a panacea where software guys pay one hardware guy for GPUs to unlock the incredible value creation of the future.
Generative AI was always set up to fail, because it was meant to be everything, was talked about like it was everything, is still sold like it’s everything, yet for all the fucking hype, it all comes down to two companies: OpenAI, and, of course, NVIDIA.
NVIDIA was, for a while, living high on the hog. All CEO Jensen Huang had to do every three months was saying “check out these numbers” and the markets and business journalists would squeal with glee, even as he said stuff like “the more you buy the more you save,” in part tipping his head to the (very real and sensible) idea of accelerated computing, but framed within the context of the cash inferno that’s generative AI, seems ludicrous.
Huang’s showmanship worked really well for NVIDIA for a while, because for a while the growth was easy. Everybody was buying GPUs. Meta, Microsoft, Amazon, Google (and to a lesser extent Apple and Tesla) make up 42% of NVIDIA’s revenue, creating, at least for the first four, a degree of shared mania where everybody justified buying tens of billions of dollars of GPUs a year by saying “the other guy is doing it!”
This is one of the major reasons the AI bubble is happening, because people conflated NVIDIA’s incredible sales with “interest in AI,” rather than everybody buying GPUs. Don’t worry, I’ll explain the revenue side a little bit later. We’re here for the long haul.
Anyway, NVIDIA is facing a problem — that the only thing that grows forever is cancer.
On September 9 2025, the Wall Street Journal said that NVIDIA’s “wow” factor was fading, going from beating analyst estimates in by nearly 21% in its Fiscal Year Q2 2024 earnings to scraping by with a mere 1.52% beat in its most-recent earnings — something that for any other company, would be a good thing, but framed against the delusional expectations that generative AI has inspired, is a figure that looks nothing short of ominous.
Per the Wall Street Journal:
Already, Nvidia’s 56% annual revenue growth rate in its latest quarter was its slowest in more than two years. If analyst projections hold, growth will slow further in the current quarter.
In any other scenario, 56% year-over-year growth would lead to an abundance of Dom Perignon and Huang signing hundreds of boobs, but this is NVIDIA, and that’s just not good enough. Back in February 2024, NVIDIA was booking 265% year-over-year growth, but in its February 2025 earnings, NVIDIA only grew by a measly 78% year-over-year.
It isn’t so much that NVIDIA isn’t growing, but that to grow year-over-year at the rates that people expect is insane. Life was a lot easier when NVIDIA went from $6.05 billion in revenue in Q4 FY2023 to $22 billion in revenue in Q4 FY2024, but for it to grow even 55% year-over-year from Q2 FY2026 ($46.7 billion) to Q2 2027 would require it to make $72.385 billion in revenue in the space of three months, mostly from selling GPUs (which make up around 88% of its revenue).
This would put Nvidia in the ballpark of Microsoft ($76 billion in the last quarter) and within the neighborhood of Apple ($94 billion in the last quarter), predominantly making money in an industry that a year-and-a-half ago barely made the company $6 billion in a quarter.
And the market needs NVIDIA to perform, as the company makes up 8% of the value of the S&P 500. It’s not enough for it to be wildly profitable, or have a monopsony on selling GPUs, or for it to have effectively 10x’d their stock in a few years. It must continue to grow at the fastest rate of anything ever, making more and more money selling these GPUs to a small group of companies that immediately start losing money once they plug them in.
While a few members of the Magnificent Seven could be depended on to funnel tens of billions of dollars into a furnace each quarter, there were limits, even for companies like Microsoft, which had bought over 485,000 GPUs in 2024 alone.
To take a step back, companies like Microsoft, Google and Amazon make their money by either selling access to Large Language Models that people incorporate into their products, or by renting out servers full of GPUs to run inference (as said previously, the process to generate an output by a model or series of models) or train AI models for companies that develop and market models themselves, namely Anthropic and OpenAI.
The latter revenue stream of which is where Jensen Huang found a solution to that eternal growth problem: the neocloud, namely CoreWeave, Lambda and Nebius.
These businesses are fairly straightforward. They own (or lease) data centers that they then fill full of servers that are full of NVIDIA GPUs, which they then rent on an hourly basis to customers, either on a per-GPU basis or in large batches for larger customers, who guarantee they'll use a certain amount of compute and sign up to long-term (i.e. more than an hour at a time) commitments.
A neocloud is a specialist cloud compute company that exists only to provide access to GPUs for AI, unlike Amazon Web Services, Microsoft Azure and Google Cloud, all of which have healthy businesses selling other kinds of compute, with AI (as I’ll get into later) failing to provide much of a return on investment.
It’s not just the fact that these companies are more specialized than, say, Amazon’s AWS or Microsoft Azure. As you’ve gathered from the name, these are new, young, and in almost all cases, incredibly precarious businesses — each with financial circumstances that would make a Greek finance minister blush.
That’s because setting up a neocloud is expensive. Even if the company in question already has data centers — as CoreWeave did with its cryptocurrency mining operation — AI requires completely new data center infrastructure to house and cool the GPUs, and those GPUs also need paying for, and then there’s the other stuff I mentioned earlier, like power, water, and the other bits of the computer (the CPU, the motherboard, the memory and storage, and the housing).
As a result, these neoclouds are forced to raise billions of dollars in debt, which they collateralize using the GPUs they already have, along with contracts from customers, which they use to buy more GPUs. CoreWeave, for example, has $25 billion in debt on estimated revenues of $5.35 billion, losing hundreds of millions of dollars a quarter.
You know who also invests in these neoclouds? NVIDIA!
NVIDIA is also one of CoreWeave’s largest customers (accounting for 15% of its revenue in 2024), and just signed a deal to buy $6.3 billion of any capacity that CoreWeave can’t otherwise sell to someone else through 2032, an extension of a $1.3 billion 2023 deal reported by the Information. It was the anchor investor ($250 million) in CoreWeave’s IPO, too.
NVIDIA is currently doing the same thing with Lambda, another neocloud that NVIDIA invested in, which also plans to go public next year. NVIDIA is also one of Lambda’s largest customers, signing a deal with it this summer to rent 10,000 GPUs for $1.3 billion over four years.
In the UK, NVIDIA has just invested $700 million in Nscale, a former crypto miner that has never built an AI data center, and that has, despite having no experience, committed $1 billion (and/or 100,000 GPUs) to an OpenAI data center in Norway. On Thursday, September 25, Nscale announced it had closed another funding round, with NVIDIA listed as a main backer — although it’s unclear how much money it put in. It would be safe to assume it’s another few hundred million.
NVIDIA also invested in Nebius, an outgrowth of Russian conglomerate Yandex, and Nebius provides, through a partnership with NVIDIA, tens of thousands of dollars’ worth of compute credits to companies in NVIDIA’s Inception startup program.
NVIDIA’s plan is simple: fund these neoclouds, let these neoclouds load themselves up with debt, at which point they buy GPUs from NVIDIA, which can then be used as collateral for loans, along with contracts from customers, allowing the neoclouds to buy even more GPUs. It’s like that Robinhood infinite money glitch…
…except, that is, for one small problem. There don’t appear to be that many customers.
There Is Less Than A Billion Dollars In AI Compute Revenue Outside of NVIDIA, Hyperscalers and OpenAI, And NVIDIA Is Using Its Compute Deals To Help Neoclouds Raise More Debt To Buy More GPUs
As I went into recently on my premium newsletter, NVIDIA funds and sustains Neoclouds as a way of funnelling revenue to itself, as well as partners like Supermicro and Dell, resellers that take NVIDIA GPUs and put them in servers to sell pre-built to customers. These two companies made up 39% of NVIDIA’s revenues last quarter.
Yet when you remove hyperscaler revenue — Microsoft, Amazon, Google, OpenAI and NVIDIA — from the revenues of these neoclouds, there’s barely $1 billion in revenue combined, across CoreWeave, Nebius and Lambda. CoreWeave’s $5.35 billion revenue is predominantly made up of its contracts with NVIDIA, Microsoft (offering compute for OpenAI), Google (hiring CoreWeave to offer compute for OpenAI), and OpenAI itself, which has promised CoreWeave $22.4 billion in business over the next few years.
This is all a lot of stuff, so I’ll make it really simple: there is no real money in offering AI compute, but that isn’t Jensen Huang’s problem, so he will simply force NVIDIA to hand money to these companies so that they have contracts to point to when they raise debt to buy more NVIDIA GPUs.
Neoclouds are effectively giant private equity vehicles that exist to raise money to buy GPUs from NVIDIA, or for hyperscalers to move money around so that they don’t increase their capital expenditures and can, as Microsoft did earlier in the year, simply walk away from deals they don’t like. Nebius’ “$17.4 billion deal” with Microsoft even included a clause in its 6-K filing that Microsoft can terminate the deal in the event the capacity isn’t built by the delivery dates, and Nebius has already used the contract to raise $3 billion to… build the data center to provide compute for the contract.
Here, let me break down the numbers:
- CoreWeave: Microsoft (60% of revenue in 2024, providing compute for OpenAI), NVIDIA (15% of its 2024 revenue), Meta, OpenAI (which picked up Microsoft's option for more future capacity), Google (providing compute for OpenAI)
- Lambda: Half of its revenue comes from Amazon and Microsoft, and now $1.5 billion over four years will come from NVIDIA, which at its current revenue ($250m in the first half of 2025) would make NVIDIA its largest customer.
- Nebius: With similar revenue to Lambda, Nebius' largest customer is now Microsoft, though it reports a number of smaller companies and institutions on their customers page.
From my analysis, it appears that CoreWeave, despite expectations to make that $5.35 billion this year, has only around $500 million of non-Magnificent Seven or OpenAI AI revenue in 2025, with Lambda estimated to have around $100 million in AI revenue, and Nebius around $250 million without Microsoft’s share, and that’s being generous.
In simpler terms, the Magnificent Seven is the AI bubble, and the AI bubble exists to buy more GPUs, because (as I’ll show) there’s no real money or growth coming out of this, other than in the amount that private credit is investing — “$50 billion a quarter, for the low end, for the past three quarters.”
Here’s Why This Is Bad
I dunno man, let’s start simple: $50 billion a quarter of data center funding is going into an industry that has less revenue than Genshin Impact. That feels pretty bad. Who’s gonna use these data centers? How are they going to even make money on them? Private equity firms don’t typically hold onto assets, they sell them or take them public. Doesn’t seem great to me!
Anyway, if AI was truly the next big growth vehicle, neoclouds would be swimming in diverse global revenue streams. Instead, they’re heavily-centralized around the same few names, one of which (NVIDIA) directly benefits from their existence not as a company doing business, but as an entity that can accrue debt and spend money on GPUs. These Neoclouds are entirely dependent on a continual flow of private credit from firms like Goldman Sachs (Nebius, CoreWeave, Lambda for its IPO), JPMorgan (Lambda, Crusoe, CoreWeave), and Blackstone (Lambda, CoreWeave), who have in a very real sense created an entire debt-based infrastructure to feed billions of dollars directly to NVIDIA, all in the name of an AI revolution that's yet to arrive.
The fact that the rest of the neocloud revenue stream is effectively either a hyperscaler or OpenAI is also concerning. Hyperscalers are, at this point, the majority of data center capital expenditures, and have yet to prove any kind of success from building out this capacity, outside, of course, Microsoft’s investment in OpenAI, which has succeeded in generating revenue while burning billions of dollars.
Hyperscaler revenue is also capricious, but even if it isn’t, why are there no other major customers? Why, across all of these companies, does there not seem to be one major customer who isn’t OpenAI?
The answer is obvious: nobody that wants it can afford it, and those who can afford it don’t need it.
It’s also unclear what exactly hyperscalers are doing with this compute, because it sure isn’t “making money.” While Microsoft makes $10 billion in revenue from renting compute to OpenAI via Microsoft Azure, it does so at-cost, and was charging OpenAI $1.30-per-hour for each A100GPU it rents, a loss of $2.2 an hour per GPU, meaning that it is likely losing money on this compute, especially as SemiAnalysis has the total cost per hour per GPU at around $1.46 with the cost of capital and debt associated for a hyperscaler, though it’s unclear if that’s for an H100 or A100 GPU.
In any case, how do these neoclouds pay for their debt if the hyperscalers give up, or NVIDIA doesn’t send them money, or, more likely, private credit begins to notice that there’s no real revenue growth outside of circular compute deals with neoclouds’ largest supplier, investor and customer? They don’t! In fact, I have serious concerns that they can’t even build the capacity necessary to fulfil these deals, but nobody seems to worry about that.
No, really! It appears to be taking Oracle and Crusoe around 2.5 years per gigawatt of compute capacity. How exactly are any of these neoclouds (or Oracle itself) able to expand to actually capture this revenue?
Who knows! But I assume somebody is going to say “OpenAI!”
Here’s an insane statistic for you: OpenAI will account for — in both its own revenue (projected $13 billion) and in its own compute costs ($16 billion, according to The Information, although that figure is likely out of date, and seemingly only includes the compute it’ll use, and not that it has committed to build, and thus has spent money on) — about 50% of all AI revenues in 2025. That figure takes into account the $400m ARR for ServiceNow, Adobe, and Salesforce; the $35bn in revenue for the Magnificent Seven from AI (not profit, and based on figures from the previous year); revenue from neoclouds like CoreWeave, Nebius, and Lambda; and the estimated revenue from the entire generative AI industry (including Anthropic and other smaller players, like Perplexity and Anysphere) for a total of $55bn.OpenAI is the generative AI industry — and it’s a dog of a company.
As a reminder, OpenAI has leaked that it’ll burn $115 billion in the next four years, and based on my estimates, it needs to raise more than $290 billion in the next four years based on its $300 billion deal with Oracle alone.
That alone is a very, very bad sign, especially as we’re three years and $500 billion or more into this hype cycle with few signs of life outside of, well, OpenAI promising people money.
Here’s A Diagram Of How Unbelievably Circular All The Money In AI Compute Has Become
Credit to Anthony Restaino for this horrifying graphic:
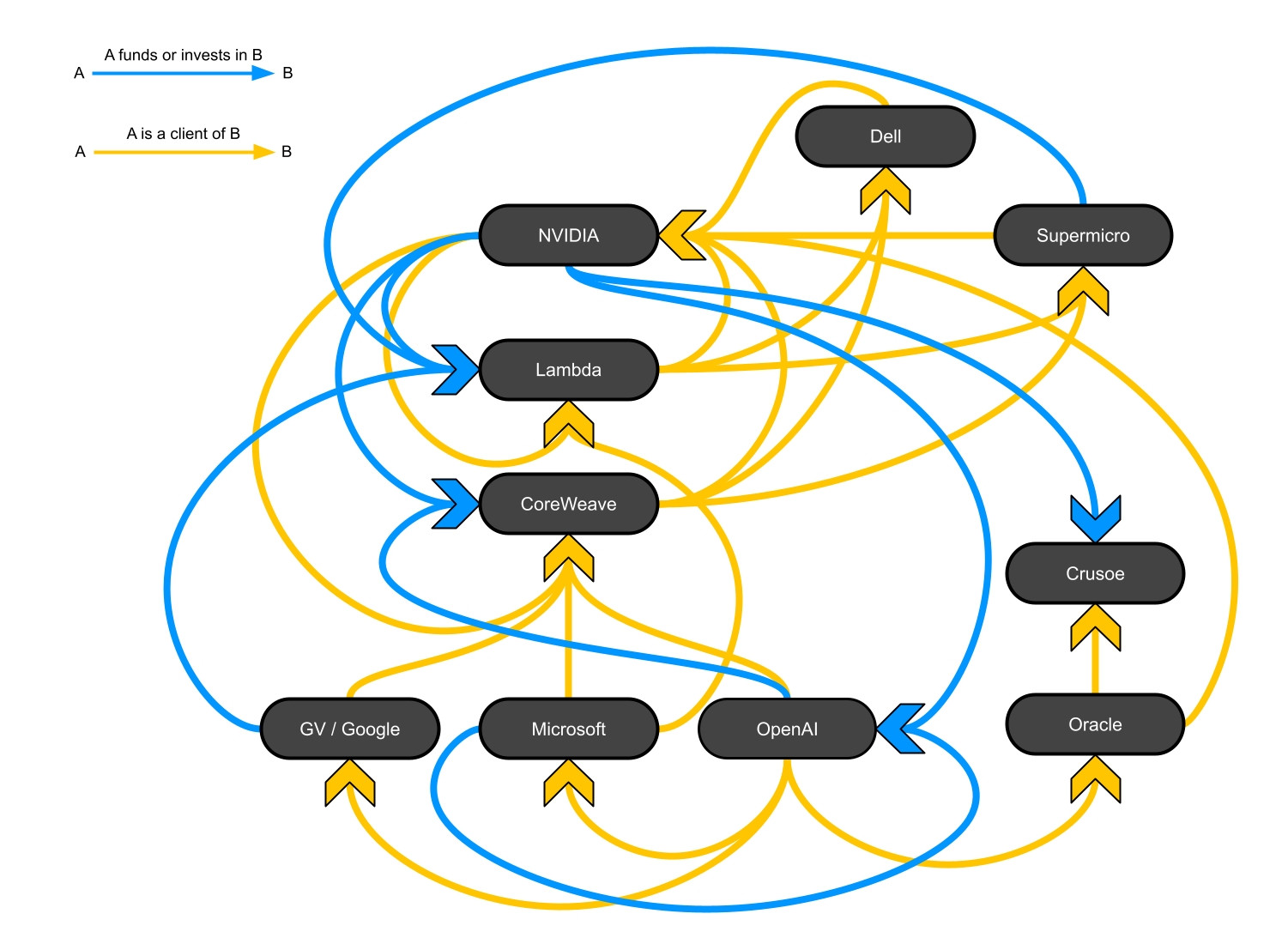
This is not what a healthy, stable industry looks like.
Alright, well, things can’t be that bad on the software side.
Right?
Right?
Every AI Company Is Unprofitable, Struggling To Grow, And Generative AI's Revenues Are Pathetic (around $61 billion in 2025 across all companies) comparable to their costs (hundreds of billions)
Mea Culpa! I have said a few times “$40 billion” is the total amount of AI revenue in 2025, and I need to correct the record. $35 billion is what hyperscalers will make this year (roughly), and when you include OpenAI, Anthropic and other startups, the amount is around $55 billion. If you include neoclouds, this number increases by about $6.1 billion. In any case, this doesn’t dramatically change my thesis.
As I covered on my premium newsletter a few weeks ago, everybody is losing money on generative AI, in part because the cost of running AI models is increasing, and in part because the software itself doesn’t do enough to warrant the costs associated with running them, which are already subsidized and unprofitable for the model providers.
Outside of OpenAI (and to a lesser extent Anthropic), nobody seems to be making much revenue, with the most “successful” company being Anysphere, makers of AI coding tool Cursor, which hit $500 million ‘annualized” (so $41.6 million in one month) a few months ago, just before Anthropic and OpenAI jacked up the prices for “priority processing” on enterprise queries, raising its operating costs as a result.
In any case, that’s some piss-poor revenue for an industry that’s meant to be the future of software. Smartwatches are projected to make $32 billion this year, and as mentioned, the Magnificent Seven expects to make $35 billion or so in revenue from AI this year.
Even Anthropic and OpenAI seem a little lethargic, both burning billions of dollars while making, by my estimates, no more than $2 billion and $6.26 billion in 2025 so far, despite projections of $5 billion and $13 billion respectively.
Outside of these two, AI startups are floundering, struggling to stay alive and raising money in several-hundred million dollar bursts as their negative-gross-margin businesses flounder.
As I dug into a few months ago, I could find only 12 AI-powered companies making more than $8.3 million a month, with two of them slightly improving their revenues, specifically AI search company Perplexity (which has now hit $150 million ARR, or $12.5 million in a month) and AI coding startup Replit (which also hit $150 million ARR in September).
Both of these companies burn ridiculous amounts of money. Perplexity burned 164% of its revenue on Amazon Web Services, OpenAI and Anthropic last year, and while Replit hasn’t leaked its costs, The Information reports its gross margins in July were 23%, which doesn’t include the costs of its free users, which you simply have to do with LLMs as free users are capable of costing you a hell of a lot of money.
Problematically, your paid users can also cost you more than they bring in as well. In fact, every user loses you money in generative AI, because it’s impossible to do cost control in a consistent manner.
AI Companies Like Anthropic Can’t Control Their Users’ Costs
A few months ago, I did a piece about Anthropic losing money on every single Claude Code subscriber, and I’ll walk you through it in a very simplified fashion:
- Claude Code is a coding environment that people use to (or, should I say, try to) build software using generative AI. It’s available as part of the $20, $100, and $200-a-month Claude subscriptions, with the more-expensive subscriptions having more generous rate limits.
- Generally, these subscriptions are “all you can eat” — you can use them as much as you want until you hit your limits, rather than paying for the actual tokens you burn.
- When I say “burn tokens,” I am describing how these models are traditionally billed. In general, you are billed at a dollar price per million input tokens (as in the user feeding data to the model to create an output) and output tokens (the output created). For example, Anthropic charges $3 per-million input and $6 per-million output tokens to use its Claude Sonnet 4 model.
- Claude Code has been quite popular, and a user created a program called “CCusage” which allowed you to see your “token burn” — the amount of tokens you were burning using Anthropic’s models — and many were seeing that they were burning in excess of their monthly spend.
- To be clear, this is the token price based on Anthropic’s own pricing, and thus the costs to Anthropic are likely not identical.
- So I got a little clever. Using Anthropic’s gross profit margins — I chose 55%, which was pretty close to the 60% that was leaked after my article — I found at least 20 different accounts of people costing Anthropic anywhere from 130% to 3,084% of their subscription.
- There is now a leaderboard called “viberank” where people compete to see how much they burn, with the current leader burning $51,291 over the course of a month.
Anthropic is, to be clear, the second-largest model developer, and has some of the best AI talent in the industry. It has a better handle on its infrastructure than anyone outside of big tech and OpenAI.
It still cannot seem to fix this problem, even with weekly rate limits.
While one could assume that Anthropic is simply letting people run wild, my theory is far simpler: even the model developers have no real way of limiting user activity, likely due to the architecture of generative AI.
I know it sounds insane, but at the most advanced level, model providers are still prompting their models, and whatever rate limits may be in place appear to, at times, get completely ignored, and there doesn’t seem to be anything they can do to stop it.
No, really. Anthropic counts amongst its capitalist apex predators one lone Chinese man who spent $50,000 of their compute in the space of a month fucking around with Claude Code. Even if Anthropic was profitable — it isn’t, and will burn billions this year — a customer paying $200-a-month running up $50,000 in costs immediately devours the margin of any user running the service that day, if not that week or month. Even if Anthropic’s costs are half the published rates, one guy amounted to 125 users’ monthly revenue.
That’s not a real business! That’s a bad business with out-of-control costs, and it doesn’t appear anybody has these costs under control.
AI Software Businesses Like Replit Are Desperate, Abusing Their Customers To Try And Juice Their Revenues
A few weeks ago, Replit — an unprofitable AI coding company — released a product called “Agent 3.” which promised to be “10x more autonomous” and offer “infinitely more possibilities,” “[testing] and [fixing] its code, constantly improving your application behind the scenes in a reflection loop.” In reality, this means you’d go and tell the model to build something and it would “go do it,” and you’ll be shocked to hear that these models can’t be relied upon to “go and do” anything.
Please note that this was launched a few months after Replit raised its prices, shifting to obfuscated “effort-based” pricing that would charge “the full scope of the agent’s work.”
Agent 3 has been a disaster. Users found tasks that previously cost a few dollars were spiralling into the hundreds of dollars, with The Register reporting one customer found themselves with a $1000 bill after a week:
"I think it’s just launch pricing adjustment – some tasks on new apps ran over 1hr 45 minutes and only charged $4-6 but editing pre-existing apps seems to cost most overall (I spent $1k this week alone)" one user told The Register.
Another user complained that “costs skyrocketed, without any concrete results”:
"I typically spent between $100-$250/mo. I blew through $70 in a night at Agent 3 launch,” another Redditor wrote, alleging the new tool also performed some questionable actions. “One prompt brute forced its way through authentication, redoing auth and hard resetting a user's password to what it wanted to perform app testing on a form," the user wrote.
As I previously reported, in late May/early June, both OpenAI and Anthropic cranked up the pricing on their enterprise customers, leading to Replit and Cursor both shifting their prices. This abuse has now trickled down to their customers.
Replit has now released an update that lets you choose how autonomous you want Agent 3 to be, which is a tacit admission that you can’t trust coding LLMs to build software. Replit’s users are still pissed off, complaining that Replit is charging them for activity when the agent doesn’t do anything, a consistent problem across its Reddit. While Reddit is not the full summation of all users across every company, it’s a fairly good barometer of user sentiment, and man, are users pissy.
Here’s Why This Is Bad
Traditionally, Silicon Valley startups have relied upon the same model of “grow really fast and burn a bunch of money, then “turn the profit lever.”
AI does not have a “profit lever,” because the raw costs of providing access to AI models are so high (and they’re only increasing) that the basic economics of how the tech industry sells software don’t make sense. I’ll reiterate something I wrote a few weeks ago:
- A Large Language Model user's infrastructural burden varies wildly between users and use cases. While somebody asking ChatGPT to summarize an email might not be much of a burden, somebody asking ChatGPT to review hundreds of pages of documents at once — a core feature of basically any $20-a-month subscription — could eat up eight GPUs at once.
- To be very clear, a user that pays $20-a-month could run multiple queries like this a month, and there's no real way to stop them.
- Unlike most software products, any errors in producing an output from a Large Language Model have a significant opportunity cost. When a user doesn't like an output, or the model gets something wrong, or the user realizes they forgot something, the model must make further generations, and even with caching (which Anthropic has added a toll to), there's a definitive cost attached to any mistake.
- Large Language Models, for the most part, lack definitive use cases, meaning that every user is (even with an idea of what they want to do) experimenting with every input and output. In doing so, they create the opportunity to burn more tokens, which in turn creates an infrastructural burn on GPUs, which cost a lot of money to run.
- The more specific the output, the more opportunities there are for monstrous token burn, and I'm specifically thinking about coding with Large Language Models. The token-heavy nature of generating code means that any mistakes, suboptimal generations or straight-up errors will guarantee further token burn.
- Even efforts to reduce compute costs — by, for example, pushing free users or those on cheap plans to smaller, less intensive models — have dubious efficacy. OpenAI’s splitter model in the GPT-5 version of ChatGPT, requires vast amounts of additional compute in order to route the user’s request to the appropriate model (with simpler requests going to smaller models, and more complex ones being shifted to reasoning models), and makes it impossible to cache part of the input. As a result, it’s unclear whether it’s saving OpenAI any money.
In simpler terms, it is very, very difficult to imagine what one user — free or otherwise — might cost, and thus it’s hard to charge them on a monthly basis, or tell them what a service might cost them on average.
This is a huge problem with AI coding environments.
Claude Code May Seem Popular, But It Only Makes $33 Million A Month — And That Was Before Rate Limits Kicked In
According to The Information, Claude Code was driving “nearly $400 million in annualized revenue, roughly doubling from a few weeks ago” on July 31 2025.
That annualized revenue works out to about $33 million a month in revenue for a company that predicts it will make at least $416 million a month by the end of the year, and for a product that has become the most-popular coding environment in the world, from the second-largest and best-funded AI company in the world.
…is that it? Is that all that’s happening here?
$33 million dollars, all of it unprofitable, after it felt, at least based on social media chatter and discussing with multiple different software engineers, that Claude Code had become ubiquitous with anything to do with LLMs.
To be clear, Anthropic’s Sonnet and Opus models are consistently some of the most popular for programming on Openrouter, an aggregator of LLM usage, and Anthropic has been consistently-named as “the best at coding.”
There Is One Popular Coding LLM — Github Copilot, With 1.8 Million Paying Subscribers — That Loses More Than $20 A Month Per User
Some bright spark out there is going to say that Microsoft’s Github Copilot has 1.8 million paying subscribers, and guess what, that’s true, and in fact, I reported it!
Here’s another fun fact: the Wall Street Journal reported that Microsoft loses “on average more than $20-a-month-per-user,” with “...some users [costing] the company as much as $80.”
And that’s for the most-popular product!
Silicon Valley’s “Replacing Engineers With LLMs” Story Is A Lie
If you believe the New York Times or other outlets that simply copy and paste whatever Dario Amodei says, you’d think that the reason that software engineers are having trouble finding work is because their jobs are being replaced by AI. This grotesque, abusive, manipulative and offensive lie has been propagated throughout the entire business and tech media without anybody sitting down and asking whether it’s true, or even getting a good understanding of what it is that LLMs can actually do with code.
Members of the media, I am begging you, stop doing this. I get it, every asshole is willing to give a quote saying that “coding is dead,” and that every executive is willing to burp out some nonsense about replacing all of their engineers, but I am fucking begging you to either use these things yourself, or speak to people that do.
I am not a coder. I cannot write or read code. Nevertheless, I am capable of learning, and have spoken to numerous software engineers in the last few months, and basically reached a consensus of “this is kind of useful, sometimes.”
However, one very silly man once said that I don’t speak to people who use these tools, so I went and spoke to three notable, experienced software engineers, and asked them to give me the straight truth about what coding LLMs can do.
Carl Brown of The Internet of Bugs:
From The Perspective Of History: The building block task of programming, going back 40+ years, is writing a block of code that takes some input, does some processing as described by some requirements, and returns some output. Code generation AIs do this pretty well, even for some extremely hard programming riddles that coders (and AI companies) like to brag about solving. However, most of the advancements in programming languages, technique, and craft in the last 40 years have been designing safer and better ways of tying these blocks together to create larger and larger programs with more complexity and functionality. Humans use these advancements to arrange these blocks in logical abstraction layers, so we can fit an understanding of the layers' interconnections in our heads as we work, diving into blocks temporarily as needed. This is where the AIs fall down. The amount of context required to hold the interconnections between these blocks quickly grows beyond the AIs’ effective short term memory (in practice, much smaller than its advertised context window size), and the AIs lack the ability to reason about the abstractions as we do. This leads to real-word code that's illogically layered, hard to understand, debug, and maintain.
CIO-speak (and/or investor) level: Code generation AIs, from an industry standpoint, are roughly the equivalent of a slightly-below-average Computer Science graduate fresh out of school, without real-world experience, only ever having written programs to be printed and graded. This might seem useful, because the tech industry hires a bunch of such graduates (or did, until recently), replacing them with AI seems like a win. But, unlike the new hires, the AIs can't learn and adapt to your code or your processes. So in 6 months, the now-former new grad is far more productive than the AI, and will continue to get better. This runs the risk of causing a crisis for the company, where the short-term favoring of chatbots over new hires drags down the long-term productivity of the more senior developers, saddled with "helpers" that will never work independently. And it hurts the whole industry over time, as fewer new hires now means fewer senior developers in a few years and, barring a miracle, we risk a shortage of people experienced enough to guide, troubleshoot and debug both the AIs and the widespread chaos the AIs' inexperience will create between now and then.
Nik Suresh of I Will Fucking Piledrive You If You Mention AI Again:
What, as a guy who does software engineering or something adjacent to it for a living, do coding LLMs actually do?:
For this, I’m going to give GenAI a complete pass on all parts of my job that aren’t writing code. They’re totally excused from not being able to interact with the business. Let’s talk about just the programming.
When we’re writing code, we’re really writing instructions for a computer to do some sort of task – usually copying information around or changing it. For example, if someone swipes a credit card, we write the steps to store their credit card information and details about the transaction. LLMs have a few obvious strengths in the instruction-writing industry. Firstly, they can write far more rapidly than any human on the planet. And secondly, due to the vast quantities of data they’re trained on, they can do things like swap between programming languages with an ease unattainable by humans, and sometimes seem to have an encyclopedic knowledge of esoteric programming knowledge.
However, under the hood, they’re simply guessing at the most likely next word in a sequence based on statistical mechanisms — trying to make this text file look like other text files it has read. Because of this, they frequently get weird and make strange errors, generally getting worse the further from “typical” the work is – i.e, they’re bad at precisely the things I’d want a custom solution for in the first place. Because of the high error rate, I still have to read and verify every line, which is frequently much slower than writing them myself.
Furthermore, getting a useful result of them can require a painstaking specification of both their immediate instructions (“write a program that charges someone’s card…”), convention (“we write out programs in Rust, following the principles for this specific book…” ) and context (“oh Christ, I have to try and explain global financial infrastructure to this stupid computer…”)
This is a substantial amount of work.
The net result is a process that will sometimes solve a thorny problem for me in a few seconds, saving me some brainpower. But in practice, the effort of articulating so much of the design work in plain English and hoping that the LLM emits code that I find acceptable is frequently more work than just writing the code. For most problems, the hardest part is the thinking, and LLMs don’t make that part any easier.
Colt Voege of No, AI is not Making Engineers 10x As Productive:
AI has fundamentally changed the landscape of software engineering forever. Right? At least that’s what everyone who’s three letter title starts with a C is telling us. Well, it has, but not in the way they think. As a Principal Engineer with 12 years of experience in corporate software development, I’m going to try to dispel some of the myths about what LLMs are doing for software development now and in the future.
First things first, let’s debunk the common narrative. No, you can’t vibe code an entire company. People who don’t know how to code can’t be engineers, even with a chatbot. AI is not making engineers 10x as productive. LLMs often function like a fresh summer intern – they are good at solving the straightforward problems that coders learn about in school, but they are unworldly. They do not understand how to bring lots of solutions to small, straightforward problems together into a larger whole. They lack the experience to be wholly trusted, and trust is the most important thing you need to fully delegate coding tasks.
How powerful is it to give every engineer in your company an intern for $200 a month per seat? Useful, surely. You can give interns problems, carefully coax them through the barriers they will inevitably run into, and end up with genuinely shippable code. I treat the LLM in my coding editor in a similar way. When I run into a problem I don’t want to do, or need some quick expertise I’m missing, I can delegate to the LLM for a bit while checking it’s work. I can and do frequently save time doing so, but these opportunities are limited and don’t scale.
If the comparison of college students to chatbots seems dehumanizing, that’s because it is. Interns are real people who learn and grow. Rising sophomores go from unprepared learners to ready to go full time in a single summer so frequently that “drop out of college and move to Mountain View” became a meme. Three years of AI model improvements and carefully adjusting my system prompt haven't come close to changing the fact that I can’t trust the damn chatbot. I have to treat it like a clever but woefully inexperienced intern who can’t learn. This is due to a fundamental limitation of how LLMs work. They do not understand problems; they digest and generate language tokens probabilistically. It’s probably impossible to build an LLM with a context window large enough to properly parse an entire mature codebase.
As an industry, we are in many ways sacrificing the long term investments in human capital for short term dopamine bursts when the LLM does something right. This will change the industry, but not in a good way – and certainly not in the way executives hope.
To Summarize: Coding LLMs Don’t Actually Replace Software Engineers, and Never Will, Due To The Inherent Unreliability Of Large Language Models
In simple terms, LLMs are capable of writing code, but can’t do software engineering, because software engineering is the process of understanding, maintaining and executing code to produce functional software, and LLMs do not “learn,” cannot “adapt,” and (to paraphrase Brown), break down the more of your code and variables you ask them to look at at once.
It’s very easy to believe that software engineering is just writing code, but the reality is that software engineers maintain software, which includes writing and analyzing code among a vast array of different personalities and programs and problems. Good software engineering harkens back to Brian Merchant’s interviews with translators — while some may believe that translators simply tell you what words mean, true translation is communicating the meaning of a sentence, which is cultural, contextual, regional, and personal, and often requires the exercise of creativity and novel thinking.
My editor, Matthew Hughes, gave an example of this in his newsletter:
I actually used to live in France (and the French-speaking part of Switzerland), and I can actually speak the language, and occasionally I’ll look up French translations to see how certain quirky bits of writing made the jump. Bits where there’s no immediately obvious or graceful way to do a literal translation.
The Harry Potter series is a good example. In French, Hogwarts is Poudlard, which translates into “bacon lice.” Why did they go with that, instead of a literal translation of Hogwarts, which would be “Verruesporc?” No idea, but I’d assume it has something to do with the fact that Poudlard sounds a lot better than Verruesporc.
Someone had to actually think about how to translate that one idea. They had to exercise creativity, which is something that an AI is inherently incapable of doing.
Similarly, coding is not just “a series of text that programs a computer,” but a series of interconnected characters that refers to other software in other places that must also function now and explain, on some level, to someone who has never, ever seen the code before, why it was done this way.
This is, by the way, why we are still yet to get any tangible proof that AI is replacing software engineers…because it can’t.
Here’s Why This Is Bad
Of all the fields supposedly at risk from “AI disruption,” coding feels (or felt) the most tangible, if only because the answer to “can you write code with LLMs” wasn’t an immediate, unilateral no.
The media has also been quick to say that AI “writes software,” which is true in the same way that ChatGPT “writes novels”. In reality, LLMs can generate code, and do some software engineering-adjacent tasks, but, like all Large Language Models, break down and go totally insane, hallucinating more as the tasks get more complex.
And, as I pointed out earlier, software engineering is not just coding. It involves thinking about problems, finding solutions to novel challenges, designing stuff in a way that can be read and maintained by others, and that’s (ideally) scalable and secure.
The whole fucking point of an “AI” is that you hand shit off to it! That’s what they’ve been selling it as! That’s why Jensen Huang told kids to stop learning to code, as with AI, there’s no point.
And it was all a lie. Generative AI can’t do the job of a software engineer, and it fails while also costing abominable amounts of money.
Coding LLMs seem like magic at first, because they (to quote a conversation with Carl Brown) make the easy things easier, but they also make the harder things harder. They don’t even speed up engineers — they actually make them slower!
Yet coding is basically the only obvious use case for LLMs.
I’m sure you’re gonna say “but I bet the enterprise is doing well!” and you are so very, very wrong.
Even Microsoft Is Failing At AI, With Only 8 Million Active Paying Microsoft 365 Copilot Subscribers Out Of 440 Million+ Users
Before I go any further, let’s establish some facts:
- In its last quarterly earnings, Microsoft made $33.1 billion in revenue in its Productivity and Business Processes segment, which includes Microsoft 365 (Word, Excel, PowerPoint, and so on), LinkedIn, its “Dynamics” business products, and its lucrative Microsoft 365 commercial division.
- As of January 2024, Microsoft’s Office 365 commercial seats grew to 400 million paying subscribers, and The Information reported in September 2024 that these had reached 440 million.
- Organizations generally pay for a particular SKU (product code) that includes a series of different pieces of software, accessing things like Word, Excel, PowerPoint, SharePoint (an internal document management system) and other business apps.
- Microsoft offers two SKUs for Copilot for commercial users — a free one called “Copilot Chat,” and “Microsoft 365 Copilot,” a $30-a-month subscription, paid annually, on top of your Microsoft 365 subscription.
All of this is to say that Microsoft has one of the largest commercial software empires in history, thousands (if not tens of thousands) of salespeople, and thousands of companies that literally sell Microsoft services for a living.
And it can’t sell AI.
A source that has seen materials related to sales has confirmed that, as of August 2025, Microsoft has around eight million active licensed users of Microsoft 365 Copilot, amounting to a 1.81% conversion rate across the 440 million Microsoft 365 subscribers.
This would amount to, if each of these users paid annually at the full rate of $30-a-month, to about $2.88 billion in annual revenue for a product category that makes $33 billion a fucking quarter.
And I must be clear, I am 100% sure these users aren’t all paying $30 a month.
The Information reported a few weeks ago that Microsoft has been “reducing the software’s price with more generous discounts on the AI features, according to customers and salespeople,” heavily suggesting discounts had already been happening. Enterprise software is traditionally sold at a discount anyway — or, put a different way, with bulk pricing for those who sign up a bunch of users at once.
In fact, I’ve found evidence that it’s been doing this a while, with a 15% discount on annual Microsoft 365 Copilot subscriptions for orders of 10-to-300 seats mentioned by an IT consultant back in late 2024, and another that’s currently running through September 30, 2025 through Microsoft’s Cloud Solution Provider program, with up to 2400 licenses discounted if you pay upfront for the year. Microsoft seems to do this a lot, as I found another example of an offer that ran from January 1 2025 through March 31 2025.
An “active” user is someone who has taken one action on Copilot in any Microsoft 365 app in the space of 28 days.
Now, I know. That word, active. Maybe you’re thinking “Ed, this is like the gym model! There are unpaid licenses that Microsoft is getting paid for!”
Fine! Let’s assume that Microsoft also has, based on research that suggests this is the case for all software companies, another 50% — four million — of paid Copilot licenses that aren’t being used.
That still makes this 12 million users, which is still a putrid 2.72% conversion rate.
So, why aren’t people paying for Copilot? Let’s hear from someone who talked to The Information:
“It’s easy for an employee to say, ‘Yes, this will help me,’ but hard to quantify how. And if they can’t quantify how it’ll help them … it’s not going to be a long discussion” over whether the software is worth paying for, Thompson said.
Microsoft 365 Copilot has been such a disaster that Microsoft will now integrate Anthropic’s models in an attempt and make them better.
Oh, one other thing: sources also confirm GPU utilization for Microsoft 365’s enterprise Copilot is barely scratching 60%. I’m also hearing that less than SharePoint — another popular enterprise app from Microsoft with 250 million users — had less than 300,000 weekly active users of its AI copilot features in August.
Microsoft Is Making Around $3 Billion On AI This Year (Outside of OpenAI)
So, The Information reported a few months ago that Microsoft’s projected AI revenues would be $13 billion, with $10 billion of that from OpenAI, leaving about $3 billion of total revenue across Microsoft 365 Copilot and any other foreseeable feature that Microsoft sells with “AI” on it.
This heavily suggests that Microsoft is making somewhere between $1.5 billion and $2 billion on Azure or Microsoft 365 Copilot, though I suppose there are other places it could be making AI revenue too. Right? I guess.
In any case, Microsoft’s net income (read: profit) in its last quarterly earnings was $27.2 billion.
Pathetic.
This Bubble Is Unlike Anything You’ve Ever Seen
One of the comfortable lies that people tell themselves is that the AI bubble is similar to the fiber boom, or the dot com bubble, or Uber, or that we’re in the “growth stage,” or that “this is what software companies do, they spend a bunch of money then “pull the profit lever.”
This is nothing like anything you’ve seen before, because this is the dumbest shit that the tech industry has ever done.
AI data centers are nothing like fiber, because there are very few actual use cases for these GPUs outside of AI, and none of them are remotely hyperscale revenue drivers. As I discussed a month or so ago, data center development accounted for more of America’s GDP growth than all consumer spending combined, and there really isn’t any demand for AI in general, let alone at the scale that these hundreds of billions of dollars are being sunk into.
The conservative estimate of capital expenditures related to data centers is around $400 billion, but given the $50 billion a quarter in private credit, I’m going to guess it breaks $500 billion, all to build capacity for an industry yet to prove itself.
And this NVIDIA-OpenAI “$100 billion funding” news should only fill you full of dread, but also it isn’t fucking finalized, stop reporting it as if it’s done, I swear to god-
Anyway, according to CNBC, “the initial $10 billion tranche is locked in at a $500 billion valuation and expected to close within a month or so once the transaction has been finalized,” with “successive $10 billion rounds are planned, each to be priced at the company’s then-current valuation as new capacity comes online.”
OpenAI Needs More Than A Trillion Dollars ($500bn in operational expenses and at Least Another $625bn-$800bn+ for data centers), And There Is Not Enough Private and Venture Capital To Pay For It
At no point is anyone asking how, exactly, OpenAI builds data centers to fill full of these GPUs. In fact, I am genuinely shocked (and a little disgusted!) by how poorly this story has been told.
Let’s go point by point:
- $10 billion is not enough for OpenAI to build a data center: The 1.1GW Abilene Texas data center being built by Oracle and Crusoe for OpenAI required $15 billion in debt, and that’s not including the $40 billion of chips needed to power it, though I question whether all of them are going into Abilene (I’ll get to that later).
- In my premium article, I estimated that a 1GW data center costs $32.5bn and takes 2.5 years to complete. That might be generous. Matt Britzman, a Senior Equity Analyst with Hargreaves Landsdown says that each gigawatt of capacity generates $50bn of revenue for Nvidia.
- If correct, this would mean that a 1GW facility could cost perhaps as much as $75bn, or even more, when taking into account the other costs, like hardware, land, construction costs, permitting, the power infrastructure that said facility requires, and more.
- One thing that puts the figure closer to that which I estimated is the price of a proposed 1GW facility, co-funded by France and the UAE, which is expected to cost between $30bn and $50bn.
- Last week, Shirin Ghaffary of Bloomberg published an article that quoted unnamed OpenAI executives where they claimed a 1GW facility costs roughly $50bn, with $35bn going exclusively to Nvidia’s chips.
- Either way you cut it, $10bn is nowhere near enough.
- OpenAI Cannot Afford To Pay For Everything It Has Promised: OpenAI will burn $115 billion in the next 4 years according to The Information, but I believe the company intentionally leaked those numbers before the announcement of its $300 billion deal with Oracle, and the subsequent deal with Nvidia. In fact, OpenAI’s compute costs and promised data center expansion amount to more than a trillion dollars, with $750 billion of that mostly the cost of compute, meaning OpenAI will need actual real money to pay for it.
- If the $50bn-per-gigawatt figure cited by OpenAI’s execs is accurate, OpenAI will need to spend $500bn to create the 10GW of capacity required to unlock the promised $100bn from Nvidia.
- Even if the true figure is closer to my estimate of $35bn-per-gigawatt, OpenAI is on the hook for $325bn — or has to find partners to finance that construction. Either way, $325 is money that it does not have.
- That figure also includes OpenAI’s $19bn commitment to the Coreweave project, it planned $41bn in spending on Microsoft Azure by the end of 2028, the $22.4bn worth of business promised Coreweave, and the yet-unknown cost of renting Google’s compute, including that powered by its TPU chips.
- I also haven’t mentioned OpenAI’s other Stargate-related projects, including Stargate UK (1GW, so likely costing between $32.5bn and $50bn, or perhaps more), Stargate Norway (which has at least $6bn in GPUs), Stargate UAE (a 200MW facility that’ll scale to 1GW, so, again, anywhere between $32.5bn and $50bn), and Stargate India (another 1GW facility costing anywhere between $32.5 and $50bn).
- Although OpenAI has partners that are funding the upfront cost of those facilities (like Nscale, G25, Cisco, Nvidia, and Softbank), said funding likely is based on the assumption — or the requirement — that it actually uses that compute.
- It’s also unclear whether OpenAI’s partners will fund all of these developments, or just a significant chunk of them, with OpenAI on the hook for a chunk of it.
- Even if it’s just a small chunk, a small chunk of a (for the sake of argument) $50bn facility is still a lot of money.
- I also haven’t mentioned OpenAI’s planned $100bn spending spree on backup capacity. It’s unclear whether that figure is factored into the aforementioned spending, or something totally different, but based on what I’ve read, I’m leaning towards it being yet another cost that OpenAI almost certainly can’t bear.
- OpenAI Is Still Yet To Convert To A For-Profit, And Must Do So By End Of Year Or Will Lose $20 Billion In Funding From SoftBank: A few weeks ago, Microsoft and OpenAI co-published an announcement that they had “signed a non-binding memorandum of understanding for the next phase of their partnership,” which the media quickly took to mean a deal was done. No deal has been done. This is literally an announcement of nothing.
- Failing to convert will also see previous equity investments transform into loans that need to be paid back, with brutal interest rates to boot.
- Venture Capital Will Run Out At The Current Rate of Investment In Six Quarters, And OpenAI Needs More Investment Than Ever: The Information recently published some worrying data from venture capitalist Jon Sakoda — that “at today’s clip, the industry would run out of money in six quarters,” adding that the money wouldn’t run out until the end of 2028 if it wasn’t for Anthropic and OpenAI. In a very real sense, OpenAI threatens the future of available capital for the tech industry.
OpenAI Claims It Will Make $200 Billion In Annual Revenue In Four Years’ Time — Its Projections Are Ridiculous, And I Don’t See How Its CFO Approved Them
To be clear, when I say OpenAI needs at least $300 billion over the next four years, that’s if you believe its projections, which you shouldn’t.
Let’s walk through its (alleged) numbers, while plagiarizing myself:
According to The Information, here's the breakdown (these are projections):
- In 2025, OpenAI will make $13 billion, but have free cash flow of negative $9 billion.
- In 2026, OpenAI will make $29 billion, but have free cash flow of negative $17 billion.
- In 2027, OpenAI will make $60 billion, but have free cash flow of negative $35 billion.
- In 2028, OpenAI will make $100 billion, but have free cash flow of negative $47 billion.
- In 2029, OpenAI will make $145 billion, but have free cash flow of negative $8 billion, somehow.
- To reiterate, OpenAI’s projections see it reduce its negative cash flow by $39bn — or one-and-a-half times 3M’s revenue from the last financial year — in a single year, while also increasing its revenue by a similar amount (give or take a few billion. Who’s counting? Certainly not OpenAI’s CFO).
- This is bonkers.
- In 2030, OpenAI will make $200 billion, and somehow have positive free cash flow of $38 billion.
OpenAI's current reported burn is $116 billion through 2030, which means there is no way that these projections include $300 billion in compute costs, even when you factor in revenue. There is simply no space in these projections to absorb that $300 billion, and from what I can tell, by 2029, OpenAI will have actually burned more than $290 billion, assuming that it survives that long, which I do not believe it will.
Don’t worry, though. OpenAI is about to make some crazy money.
Here are the projections that CFO Sarah Friar signed off on:
- In 2026, OpenAI will make $30 billion in revenue, or just under the $34 billion that Salesforce made in 2024.
- In 2027, OpenAI will make $60 billion, or $2.6 billion more than the $57.4 billion Oracle made in its Fiscal Year 2025, or $8.4 billion more than Broadcom made in 2024.
- In 2028, OpenAI will make $100 billion, or $2.31 billion more than Tesla made in 2024, or $11.66 billion more than TSMC — the single-largest chip manufacturer in the world — made in 2024.
- In 2029, OpenAI will make $145 billion, or $14.5 billion dollars more than the $130.5 billion that NVIDIA made in its Fiscal Year 2025.
- In 2030, OpenAI will make $200 billion, or $35.5 billion more than the $164.50 billion that Meta made last year.
Just so we are clear, OpenAI intends to 10x its revenue in the space of four years, selling software and access to models in an industry with about $60 billion of revenue in 2025. How will it do this? It doesn’t say.
I don’t know OpenAI CFO Sarah Friar, but I do know that signing off on these numbers is, at the very least, ethically questionable.
Putting aside the ridiculousness of OpenAI’s deals, or its funding requirements, Friar has willfully allowed Sam Altman and OpenAI to state goals that defy reality or good sense, all to take advantage of investors and public markets that have completely lost the plot.
I need to be blunter: OpenAI has signed multiple different deals and contracts for amounts it cannot afford to pay, that it cannot hope to raise the money to pay for, that defy the amounts of venture capital and private credit available, all to sustain a company that will burn $300 billion and has no path to profitability of any kind.
The NVIDIA-OpenAI Announcement Is Bullshit, And No, NVIDIA Did Not “Give OpenAI $100 Billion” — In Fact, $90 Billion Of The Funding Is Contingent On OpenAI Building $125 Billion Of Data Centers with $200 Billion GPUs
So, as I said above, CNBC reported on September 23, 2025 that the NVIDIA deal will be delivered in $10 billion tranches, the first of which is “expected to close within a month,” and the rest delivered “as new capacity comes online.” This is, apparently, all part of a plan to build 10GW of data center capacity with NVIDIA.
A few key points:
- OpenAI is not being sent $100 billion.
- OpenAI has not been sent anything.
- To get more than $10 billion, OpenAI will have to build a gigawatt of data center capacity.
- Nobody is talking about where these data centers are going to be.
So, let’s start simple: data centers take forever to build.
As I said previously, based on current reports, it’s taking Oracle and Crusoe around 2.5 years per gigawatt of data center capacity, and nowhere in these reports does one reporter take a second to say “hey, what data centers are you talking about?” or “hey, didn’t Sam Altman say back in July that he was building 10GW of data center capacity with Oracle?”
But wait, now Oracle and OpenAI have done another announcement that says they’re only doing 7GW, but they’re “ahead of schedule” on 10GW?
Wait, is NVIDIA’s 10GW the same 10GW as Oracle and OpenAI are working on? Is it different? Nobody seems to know or care!
Anyway, I cannot be clear enough how unlikely it is that (as NVIDIA has said) “the first gigawatt of NVIDIA systems will be deployed in the second half of 2026,” and that’s if it has bought the land and got the permits and ordered the construction, none of which has happened yet.
But let’s get really specific on costs!
Crusoe’s 1.2GW of compute for OpenAI is a $15 billion joint venture, which means a gigawatt of compute runs about $12.5 billion. Abilene’s eight buildings are meant to hold 50,000 NVIDIA GB200 GPUs and their associated networking infrastructure, so let’s say a gigawatt is around 333,333 Blackwell GPUs. Though this math is a little funky due to NVIDIA promising to install its new Rubin GPUs in these theoretical data centers, that means these data centers will require a little under $200 billion worth of GPUs. By my maths that’s $325 billion.
I’m so tired of this.
OpenAI Needs More Than A Trillion Dollars In The Next Four Years — $325 Billion To Build The Data Centers Necessary To Receive $100 Billion In Funding From NVIDIA, $300 Billion It Owes Oracle, $100 Billion In Backup Compute Servers, Microsoft’s Compute, Broadcom, And Others
A number of you have sent me the following image with some sort of comment about how “this is how it’ll work,” and you are wrong, because this is neither how it works nor how it will work nor accurate on any level.

In the current relationship, NVIDIA Is Not Sending OpenAI $100 Billion, nor will it send it that much money, because 90% of OpenAI’s funding is gated behind building 9 or 10 gigawatts of data center capacity.
In the current relationship, OpenAI does not have the money to pay Oracle.
Also, can Oracle even afford to give that much money to NVIDIA? It had negative free cash flow last quarter, already has $104 billion in debt, and its biggest new customer cannot afford a single fucking thing it’s promised. The only company in this diagram that actually can afford to do any of this shit is NVIDIA, and even then it only has $56 billion cash on hand.
In any case, as I went over on Friday, OpenAI has promised about a trillion dollars between compute contracts across Oracle, Microsoft, Google and CoreWeave, 17 Gigawatts of promised data centers in America between NVIDIA and “Stargate,” several more gigawatts of international data centers, custom chips from Broadcom, and their own company operations.
How exactly does this get paid for?
Nobody seems to ask these questions! Why am I the asshole doing this? Don’t we have tech analysts that are meant to analyse shit? AHhhhh-
We’re In A Bubble, Whether You Like It Or Not
Every time I sit down to write about this subject the newsletters seem to get longer, because people are so painfully attached to the norms and tropes of the past. This post is, already, 17,500 words — a record for this newsletter — and I’ve still not finished editing and expanding it.
What we’re witnessing is one of the most egregious wastes of capital in history, sold by career charlatans with their reputations laundered by a tech and business media afraid to criticize the powerful and analysts that don’t seem to want to tell their investors the truth. There are no historic comparisons here — even Britain’s abominable 1800s railway bubble, which absorbed half of the country’s national income, created valuable infrastructure for trains, a vehicle that can move people to and from places.
GPUs are not trains, nor are they cars, or even CPUs. They are not adaptable to many other kinds of work, nor are they “the infrastructure of the future of tech,” because they’re already quite old and with everybody focused on buying them, you’d absolutely see one other use case by now that actually mattered. GPUs are expensive, power-hungry, environmentally destructive and require their own kinds of cooling and server infrastructure, making every GPU data center and environmental and fiscal bubble unto themselves.
And, whereas the Victorian train infrastructure still exists in the UK — though it has been upgraded over the years — a GPU has a limited useful lifespan. These are cards that can — and will — break after a period of extended usage, whether that period is five years or later, and they’ll inevitably be superseded by something better and more powerful, meaning that the resale value of that GPU will only go down, with a price depreciation that’s akin to a new car.
I am telling you, as I have been telling you for years, again and again and again, that the demand is not there for generative AI, and the demand is never, ever arriving. The only reason anyone humours any of this crap is the endless hoarding of GPUs to build capacity for a revolution that will never arrive.
Well, that and OpenAI, a company built and sold on lies about ChatGPT’s capabilities. ChatGPT’s popularity — and OpenAI’s hunger for endless amounts of compute — have created the illusion of demand due to the sheer amount of capacity required to keep their services operational, all so they can burn $8 billion or more in 2025 and, if my estimates are right, nearly a trillion dollars by 2030.
This NVIDIA deal is a farce — an obvious attempt by the largest company on the American stock market to prop up the one significant revenue-generator in the entire industry, knowing that time is running out for it to create new avenues for eternal growth. I’d argue that NVIDIA’s deal also shows the complete contempt that these companies have for the media. There are no details about how this deal works beyond the initial $10 billion, there’s no land purchased, no data center construction started, and yet the media slurps it down without a second thought.
I am but one man, and I am fucking peculiar. I did not learn financial analysis in school, but I appear to be one of the few people doing even the most basic analysis of these deals, and while I’m having a great time doing so, I am also exceedingly frustrated at how little effort is being put into prying apart these deals.
I realize how ridiculous all of this sounds. I get it. There’s so much money being promised to so many people, market rallies built off the back of massive deals, and I get that the assumption is that this much money can’t be wrong, that this many people wouldn’t just say stuff without intending to follow through, or without considering whether their company could afford it.
I know it’s hard to conceive that hundreds of billions of dollars could be invested in something for no apparent reason, but it’s happening, right god damn now, in front of your eyes, and I am going to be merciless on anyone who attempts to write a “how could we see this coming?”
Generative AI has never been reliable, has always been unprofitable, and has always been unsustainable, and I’ve been saying so since February 2024. The economics have never made sense, something I’ve said repeatedly since April 2024, and when I wrote “How Does OpenAI Survive?” in July 2024, I had multiple people suggest I was being alarmist.
The World’s Private Credit and Venture Capital Cannot Afford OpenAI
Here’s some alarmism for you: the longer it takes for OpenAI to die, the more damage it will cause to the tech industry.
On Friday, when I put out my piece on OpenAI needing a trillion dollars, I asked analyst Gil Luria if the capital was there to build the 17 Gigawatts that OpenAI had allegedly planned to build.
He said the following:
No of course there isn't enough capital for all of this. Having said that, there is enough capital to do this for at least a little while longer.
That doesn’t sound good!
Anyway, as I discussed earlier, venture capital could run out in six quarters, with investor and researcher Jon Sakoda estimating that there will only be around $164 billion of dry powder (available capital) in US VC firms by the end of 2025.
In July, The French Tech Journal reported (using Pitchbook data) that global venture capital deal activity reached its lowest first-half total since 2018, with $139.4 billion in deal value in the first half of 2025, down from $183.4 billion in the first half of 2024, meaning that any further expansion or demands for venture capital from OpenAI will likely sap the dwindling funds available from other startups.
Things get worse when you narrow things to US venture capital. In a piece from April, EY reported that VC-backed investment in US companies hit $80 billion in Q1 2025, but “one $40 billion deal” accounted for half of the investment — OpenAI’s $40 billion deal of which only $10 billion has actually closed, and that didn’t happen until fucking June. Without the imaginary money from OpenAI, US venture would have declined by 36%.
The longer that OpenAI survives, the longer it will sap the remaining billions from the tech ecosystem, and I expect it to extend its tendrils to private credit too. The $325 billion it needs just to fulfil its NVIDIA contract, albeit over 4 years, is an egregious sum that I believe exceeds the available private capital in the world.
Let’s get specific, and check out the top 10 private equity firms’ available capital!
- Blackstone, as of writing this sentence, has about $39 billion available to invest. An article from the Wall Street Journal from April said it had $177 billion available, which means it’s approaching the point where they just don’t have the cash to issue.
- KKR has, as of writing this sentence, has $55 billion available to invest.
- Carlyle Group has, as of August 2025, has $89 billion available to invest.
- Swedish PE firm EQT had around €50 billion as of July available to invest, or around $59 billion.
- It’s not clear how much Thoma Bravo has, but this release suggests it’s recently raised $34.4 billion.
- As of August, TPG had $63 billion available to invest.
- As of March 2025, CVC Capital partners had around 40 billion euro ($47 billion) in available capital to invest.
- It’s unclear how much HG Capital has available, but reports suggest it’s been trying to raise €24 billion (or $28.35 billion).
- It’s unclear how much Hellman & Friedman have available to invest, but it raised a $24.4 billion fund last year.
- It’s unclear how much Clayton, Dubilier & Rice have available to invest, but it raised a $26 billion fund in August 2023.
- Insight Partners closed a $12.5 billion fund in January 2025. It is otherwise unclear how much they have to invest.
Assuming that all of this capital is currently available, the top 10 private equity firms in the world have around $477 billion of available capital.
We can, of course, include investment banks — Goldman Sachs had around $520 billion cash in hand available at the end of its last quarter, and JPMorgan over $1.7 trillion, but JP Morgan has only dedicated $50 billion in direct lending commitments as of February 2025, and while Goldman Sachs expanded its direct private credit lending by $15 billion back in June, that appears to be an extension of its “more than $20 billion” direct lending close from mid-2024.
Include both of those, and that brings us up to — if we assume that all of these funds are available — $562 billion in capital and about $164 billion in US venture available to spend, and that’s meant to go to more places than just OpenAI.
Sure, sure, there’s more than just the top 10 private equity firms and there’s venture money outside of the US, but what could it be? Like, another $150 billion?
You see, OpenAI needs to buy those GPUs, and it needs to build those data centers, and it needs to pay its thousands of staff and marketing and sales costs too. While OpenAI likely wouldn’t be the ones raising the money for the data centers — and honestly, I’m not sure who would do it at this point? — somebody is going to need to build TWENTY GIGAWATTS OF DATA CENTERS if we’re to believe both Oracle and NVIDIA
You may argue that venture funds and private credit can raise more, and you’re right! But at this point, there have been few meaningful acquisitions of AI companies, and zero exits from the billions of dollars put into data centers.
Even OpenAI admits in its own announcement about new Stargate sites that this will be a “$400 billion investment over 3 years.” Where the fuck is that money coming from? Is OpenAI really going to absorb massive chunks of all available private credit and venture capital for the next few years?
And no, god, stop saying the US government will bail this out. It will have to bail out hundreds of billions of dollars, there is no scenario where it’s anything less than that, and I’ve already been over this.
While the US government has spent equivalent sums in the past to support private business (the total $440 billion dispersed during the Great Recession’s TARP program, where the Treasury bought toxic assets from investment banks to stop them from imploding a la Lehman, springs to mind), it’s hard to imagine any case where OpenAI is seen as vital to the global financial system — and the economic health of the US — as the banking system.
Sure, we spent around $1tn — if we’re being specific, $953bn — on the Paycheck Protection Program during the Covid era, but that was to keep people employed at a time when the economy outside of Zoom and Walmart had, for all intents and purposes, ceased to exist. There was an urgency that doesn’t apply here. If OpenAI goes tits up, Softbank loses some money — nothing new there — and Satya Nadella has to explain why he spent tens of billions of dollars on a bunch of data centers filled with $50,000 GPUs that are, at this point, ornamental.
And while there will be — and have been — disastrous economic consequences, they won’t be as systemically catastrophic as that of the pandemic, or the global financial crisis. To be clear, it’ll be bad, but not as bad.
And there’s also the problem of moral hazard — if the government steps in, what’s to stop big tech chasing its next fruitless rainbow? — and optics. If people resented bailing out the banks after they acted like profligate gamblers and lost, how will they feel bailing out fucking Sam Altman and Jensen Huang?
I Need You To Listen To Me
I do apologize for the length of this piece, but the significance of this bubble requires depth.
There is little demand, little real money, and little reason to continue, and the sheer lack of responsibility and willingness to kneel before the powerful fills me full of angry bile. I understand many journalists are not in a position where they can just write “this shit sounds stupid,” but we have entered a deeply stupid era, and by continuing to perpetuate the myth of AI, the media guarantees that retail investors and regular people’s 401Ks will suffer.
It is now inevitable that this bubble bursts. Deutsche Bank has said the AI boom is unsustainable outside of tech spending “remaining parabolic,” which it says “is highly unlikely,” and Bain Capital has said that $2 trillion in new revenue is needed to fund AI’s scaling, and even that math is completely fucked as it talks about “AI-related savings”:
Even if companies in the US shifted all of their on-premise IT budgets to cloud and reinvested the savings from applying AI in sales, marketing, customer support, and R&D into capital spending on new data centers, the amount would still fall short of the revenue needed to fund the full investment, as AI’s compute demand grows at more than twice the rate of Moore’s Law, Bain notes.
Even when stared in the face by a ridiculous idea — $2 trillion of new revenue in a global software market that’s expected to be around $817 billion in 2025 — Bain still oinks out some nonsense about the “savings from applying AI in sales, marketing, customer support and R&D,” yet another myth perpetuated I assume to placate the fucking morons sinking billions into this.
Every single “vibe coding is the future,” “the power of AI,” and “AI job loss” story written perpetuates a myth that will only lead to more regular people getting hurt when the bubble bursts. Every article written about OpenAI or NVIDIA or Oracle that doesn’t explicitly state that the money doesn’t exist, that the revenues are impossible, that one of the companies involved burns billions of dollars and has no path to profitability, is an act of irresponsible make believe and mythos.
I am nobody. I am not a financier. I am not anybody special. I just write a lot, and read a lot, and can do the most basic maths in the world. I am not trying to be anything other than myself, nor do I have an agenda, other than the fact that I like doing this and I hate how this story is being told. I never planned for this newsletter to get this big, and now that it has, I’m going to keep doing the same thing every week.
I also believe that the way to stop this happening again is to have a thorough and well-sourced explanation of everything as it happens, ripping down the narratives as they’re spun and making it clear who benefits from them and how and why they’re choosing to do so. When things collapse, we need to be clear about how many times people chose to look the other way, or to find good faith ways to interpret bad faith announcements and leak.
So, how could we have seen this coming?
I don’t know. Did anybody try to fucking look?
